
Inova Genomes : Sequenced Whole Genome Data
- Posted at 2016/09/07 10:42
- Filed under 제품소식
Inova Translational Medicine Institute
Inova Genomes
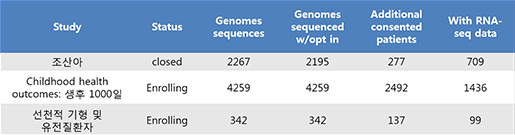
ITMI에서 선보인 Inova Genomes는 다양한 인종 및 다양성을 가지는 human whole genome 시퀀싱 결과와 개개인의
진료 기록 정보(진료기록 정보 외에는 모두 기밀)가 함께 수집된 데이터베이스이며 약 2,100건의 가계 정보 및 약
7,000명의 whole genome sequence를 가지고 있으며 매 년 2,500명 정도의 데이터들이 추가되고 있습니다.
환자의 식별은 불가능하지만 각 정보가 Electronic Health Record와 연결이 되어있으며 증상에 대한 문진데이터,
demographics, 처방이나 가계에 대한 정보들도 포함되어 있습니다. 또한 환자와 환자 가족들의 동의하에 등록이 되어 있고
시간이 지남에 따라 동일 환자의 데이터 업데이트가 가능합니다. 또한 100개 이상의 국가에서 다양한 가족의 정보 및 모든 주요
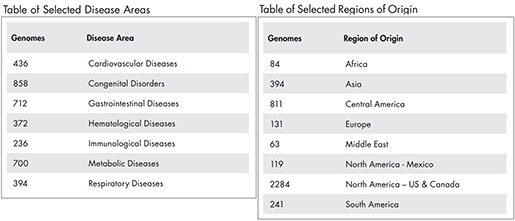
기관계의 다양한 phenotype 데이터를 보유하고 있습니다. 뿐만 아니라 RNA-seq, miRNA이나 methylation
데이터 같은 실험데이터들도 포함하여 유전체 레벨 외의 분석을 위한 데이터셋으로도 활용이 가능하며, 양질의
pre-annotated, pre-computed 실험적 데이터를 제공합니다.
Data-set
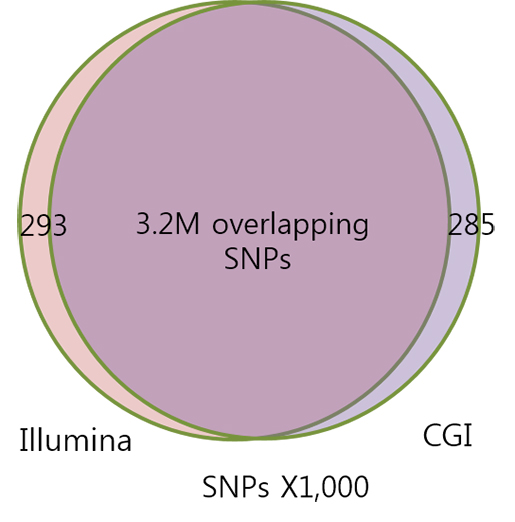
전체 데이터의 30%는 Complete Genomics 데이터 셋(coverage=60X)이며, 나머지 70% 데이터는
Illumina 데이터 셋(coverage=40X)으로 구성되어 있습니다. 그 중 Trio 데이터셋 62개, quartet 데이터
2개는 Complete Genomics나 Illumina 두 개의 플랫폼에서 모두 진행하였습니다. 아래 그림1 에서 보시면
320만개의 SNP가 공통적으로 발견이 되어 데이터의 높은 신뢰성을 보여줍니다.
Data-field
해당 데이터베이스 내에는 생 후 1000일 간의 종적연구를 위해 아래와 같은 다양한 데이터필드도 존재합니다.
- Demographics : age, gender, ethnic background
- Personal & family health history : family history cancer/diabetes/cardiac types
- Treatment/pharmaceutical records : drug name, dose, frequency
- Laboratory & diagnostic test results : glucose level, CBCs
- Clinical data : BMI, height
- Clinical encounter : Admission to NICU
- Etc.
점점 더 저렴해지고 있는 시퀀싱 비용으로 규칙 없이 시퀀싱 데이터만 빠르게 생산되는 현재 시대에 공개되어 있는 데이터는 많은데 비해 자세한 정보가 없어 활용하기 힘든 의미 없는 데이터들뿐인 요즘. 특히나 다양한 케이스의 trio 데이터를 찾기는 더더욱 힘드셨을 거라고 생각됩니다. Inova Genomes에서는 지금 우리가 겪고 있는 고민들을 해결해 줄 수 있도록 데이터 정보에 대한 체계화 및 데이터의 계속적인 업데이트, 다양한 trio 데이터셋의 제공으로 human 분야의 유전체 연구에 날개를 달아드릴 것입니다.
서지혜 컨설턴트
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/219
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

