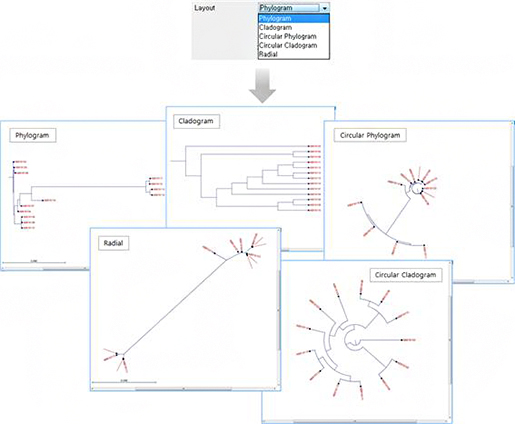
제3기 人Co INTERNSHIP 수료생 이영호
첫째 날~ 수원의 날씨는 생각보다 좋았다. 해가 뜨진 않았지만 습하지 않고 시원한 바람이 불었던 걸로 기억난다. 마을버스(대구에는
없는)에서 시내버스로 환승하며 도착한 수원산업단지 그리고 (주)인실리코젠, 나의 인생에서 첫 번째 인턴십이 시작되던 날이다.
이번 인턴십 제3기의 총 인원은 나를 포함해 4명!
신기하게도 상명대학교 2명, 영남대학교 2명으로 초반부터 대립(?)되는 구도가 형성되었다고 선배님들께서 말씀하셨지만 이상하게도 우리들은 점점 더 가깝게 친해져서 회식도 하고 서로 도와주는 공생 관계로 4주를 함께 지냈다. 어쩌면 우리가 교육
받았던 생물정보 분석 프로그램들이 단합하지 않고 혼자 하기에는 너무 힘든 과정이었기에 서로 지식을 공유하면서 더 친해질 수 있지
않았을까 하는 생각도 든다.
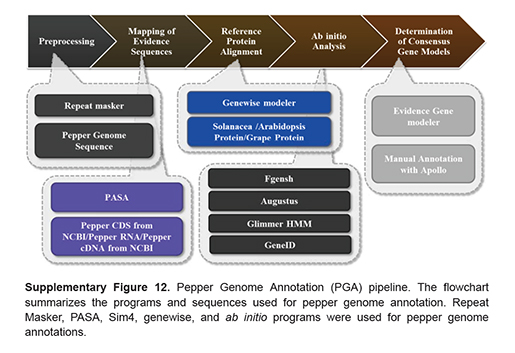
CLC Main Workbench, CLC
Genomic Workbench란 DNA, RNA, Protein 서열을 기반으로 여러 가지 정보를 얻어내고 그 정보를 통해
다양한 database를 구축하기 위한 생물정보 분석 프로그램이다. 내가 생각 했을 때 다양하게 분석된 생물정보 데이터는
database 구축을 통해 최종적으로 인간의 수명과 건강을 얻기 위함이 아닐까 싶다. 그런 의미에서 위의
2가지 프로그램들은 우리들이 원하는 목표의 밑거름이 될 수 있는 아주 좋은 도구가 될 것이다.
이런 도구들을 공부하는데 많은 도움을 주신 분들이
계시지만 특히 김경윤 주임님, 심재영 주임님, 송하나 선배님, 김경아 선배님들께 감사의 말씀을 전해드리고 싶다. 또 회사 생활에
대한 진심어린 충고와 조언을 아끼지 않고 해주신 임천안 이사님, 정은미 이사님 두분께도 너무나 감사드린다. 회사일 때문에 너무
바쁜 와중에도 우리 인턴들을 너무 잘 챙겨주시고 신경써주셔서 오히려 우리들이 모든 분들께 피해를 끼치는 게 아닌가 싶어 죄송할
때도 많았다. 조금 아쉬운 게 있었다면 나에 멘토이신 조아영 주임님의 분야는 디자인 쪽이셔서 교육내용에 대한 교류는 하지 못했지만
항상 친절하고 정답게 나를 챙겨주시고 좀 더 쉽게 회사에 적응 할 수 있도록 많은 도움을 주셨다. 마지막으로 (주)인실리코젠 최남우 대표님! 회사에 오기 전에 미리 홈페이지를 통해 사진을 보면서 느꼈었지만 외모도 너무 동안이시고 목소리도
다정다감 하셨다. 그래서인지 대표님과 첫 면담을 할 때 좀 더 편안하게 대화를 나눌 수 있었고 회사에 대한 믿음도
확고해졌다.
그렇게 1주차, 2주차 ,3주차, 4주차 시간이 지나면
지날수록 나 자신이 많이 변화하고 있다는 걸 스스로 느낄 수 있었다. 물론 짧은 인턴십 과정 중에서 배우게 되는 교육이나 회사
업무 등을 다 이해하고 습득하기에는 힘들 것이다. 하지만 난 이번 한 달 과정을 통해서 너무나 많은 경험을 할 수 있었던 것
같다. 첫째, 집을 나와 타지에서 자취하면서 생활하는 능력, 둘째, 규칙적인 식습관과 생활습관, 셋째, 직장에서의 예의범절과
대인관계, 넷째, 프리젠테이션 연습 등 평소에 경험하지 못했던 많은 것들을 여기서 배울 수 있게 되었다.
이 모든 경험들이
내가 앞으로 나아가야 할 방향에서 많은 힘이 될 것이라고 믿는다.
(주)인실리코젠, 그리고 대표님을 비롯한 모든 직원 분들과의 좋은 인연에 감사드립니다. 또 앞으로 더 좋은 인연이 되고 싶고 그렇게 될 수 있을 거라고 믿습니다. 감사드립니다.
제3기 人Co INTERNSHIP 수료생 윤선영

(주)인실리코젠의 人Co INTERNSHIP은 저에게 있어 사회 생활의 첫걸음이며, 한층 성장하는 계기가 되었습니다. 인턴십에
지원하기 위해 처음으로 자기소개서를 작성하고 면접을 보고, 직장 생활이 어떤 것인지도 알게 되었습니다. 조교로 계셨던 유승일
선배님이 석사 졸업후 취직했다는 소식과 함께, 그 회사에서 인턴십 프로그램을 진행한다는 교수님의 소개로 인해 (주)인실리코젠이라는
회사를 처음 접하게 됬습니다. 어떤 일을 하는 회사인지 알고 싶어 먼저 홈페이지를 찾아보게 되었는데, 깔끔한 페이지 구성과
블로그를 통해 회사소식에 대한 여러 내용들을 볼 수 있었습니다. 또한 설립된 지 얼마되지는 않았지만 연혁으로 미루어 봤을 때,
비약적인 발전을 하고 있는 회사라는 점도 눈에 띄였습니다. ‘한 번쯤 이런 회사에서 실무적인 것을 경험하고 배운다면 내 인생에
있어 많은 것이 도움이 되겠구나’ 생각이 들어 망설임 없이 지원했던 기억이 납니다.
일산에서 수원까지 많이 먼 거리는 아니지만 출근시간도
빠르고, 처음으로 하는 사회생활인 만큼 열심히 해보고자 수원역 근처에 방을 얻어 한달 동안의 인턴 생활을 시작하게 되었습니다.
입사 첫 날 가장 먼저 모든 분들께 인사를 드리며 명함을 받았는데, ‘단순히 인턴이라 생각하고 지나칠 수 있었던 부분인데 역시
인실리코젠에서는 사람 사이의 관계를 소중히 생각하는구나’ 라고 느꼈습니다. 한달이라는 짧은 기간 동안 인실리코젠의 人Co
가치체계에 걸맞게 사람을 중요시하는 회사라는 점을 확실히 느꼈습니다.
첫 주에는 회사소개와 사회 생활을 어떻게 해야 하는지에
대한 기본적인 교육을 받았습니다. 면접을 보기 전에 미리 홈페이지를 통해 간략하게 보았던 내용에 대해서 자세한 설명을 들으니,
훨씬 이해도 잘 되었고 무슨 일을 하는 회사인지에 대해 확실하게 알게 되었습니다. 또 사회 초년생에게 필요한 조언과 충고를 해주신
임천안 이사님과 직장 생활에서 꼭 필요한 예절을 가르쳐주신 정은미 이사님의 말씀이 아직도 기억에 납니다. 면접을 볼 당시에도
그리고 한 달동안 저희를 대할 때 항상 웃음을 잃지 않으셨던 정은미 이사님의 모습을 본받아야겠다고 생각했습니다.
일주일 뒤 수요세미나에서 자기소개 발표 시간이 있었는데,
어떻게 하면 지루하지 않은 발표를 할까 고민을 믾이 했었습니다. 첫 발표라 긴장도 많이 되었지만 다행히도 재미있게 들어주셔서
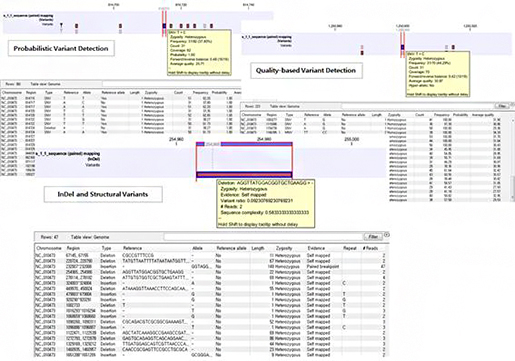
발표하는 동안 떨지 않고 무사히 마무리 할 수 있었습니다. 둘째주와 셋째주는 생물정보 통합 분석 소프트웨어인 CLC Main
Workbench와 CLC Genomic Workbench를 통하여 생물정보의 기초에 대해 배웠습니다. 갈수록 어려워지는 내용을
배울 때마다 좌절하는 순간이 왔지만, 그럴수록 저희를 위해 열심히 교육해주시는 분들 때문에 더욱 힘이 났습니다.
인턴십을 시작한지도 벌써 한 달이 다되어갑니다. 인턴십
프로그램에 참가하여
저의 부족한 점이 무엇인지 깨달을 수 있었고, 이런 깨달음을 통해 앞으로 채워나가야 할 점들을 확실히
알았습니다. 어떻게 보면 비록 한 달이라는 짧은 시간 동안 이론과 생물정보분야에 대해 많은 내용을 배우고 가지는 못하지만 사람을
대하는 방법과 사회 생활을 어떻게 해야 하는지에 대해서는 확실히 배우고 가는 것 같습니다. 그리고 한 달동안 같이 공부했던 인턴십
3기 분들과 저희에게 좋은 말씀을 해주시고 이끌어주셨던 (주)인실리코젠의 모든 분들 잊지 못할 것 같습니다. 마지막으로 이런 인턴십
프로그램을 계획하시고 좋은 경험을 할 수 있게 해주셔서 감사합니다.
제3기 人Co INTERNSHIP 수료생 이수민
안녕하세요. 人Co INTERNSHIP 프로그램에 참여한 이수민입니다. 교수님의 추천과 학교의 현장학습 제도를 통해서 (주)인실리코젠의 人Co INTERNSHIP 프로그램을 시작하게 되었습니다. 선배님이 보내 주신 자료와 교수님의 설명을 통해 처음으로
Bioinformatics 분야에 대해서 알게 되었고 가서 한 달 동안 생물정보에 대해 열심히 배우고 막연한 두려움만 가지고
있던 사회생활을 경험하여 성장해서 돌아오겠다고 다짐하였습니다. 그렇게 기대 반, 두려움 반으로 대구에서 수원에 오게 되었습니다. 첫
출근 낯선 출근길, 장소, 사람들, 모든 것이 낯설게 느껴졌습니다. 사실 회사에 오기 전 회사 홈페이지에서 '사람을 중시 한다는
가치' 가 너무 마음에 들었습니다. 아니나 다를까 역시 회사 직원분들 모두 친절하게 대해 주시고 회사 분위기도 제가 평소에
생각해오던 분위기와 다르게 화목했습니다. 그리고 떨렸던 면담시간에 대표이사님께서 저희를 편하게 해주시고 부담감을 줄일 수 있게
해주셔서 그런지 이런 좋은 환경 속에 점차 길도 익숙해지고 금방 적응할 수 있었던 것 같습니다. 그리고 첫주 위키, OJT,
사회생활의 예절 등 익숙하지 않은 것을 접하고 배우게 되었습니다. 또한 사원의 마음가짐이라는 책을 읽게 되었습니다. 사실 저는
지금 배우고 있는 생물정보 분석 툴도 중요하지만 이 첫 주에 읽은 책과 교육도 정말 중요하다고 생각합니다. 저는 책을 읽고
독후감을 쓰면서 제가 잘못 생각하고 있던 마음가짐을 배우게 되었고 정은미 이사님과 임천안 이사님의 사회생활 교육으로 제가 잘못하고
있던, 어쩌면 처음 사회생활을 했다면 독이 되었을 부분을 알게 되었습니다. 아마 사회의 초심자인 인턴에게는 정말 중요한 첫 주
였다고 생각합니다.
두번째 주 - 이제 본격적으로 CLC Main
Workbench 프로그램을 통해 생물정보의 기초를 다루고 저희를 회사 모든 분들에게 알리는 자기소개를 준비하게 되었습니다. 나름
창의적이게 하고 싶어서 열심히 준비 하였습니다. 발표 전 이제 다소 지루 할 수 있는 가장 부담되는 마지막 순서였습니다.
그리고 15분 준비했는데 아침에 7분안에 해야된다는 충격적인 소식을 들었습니다. 일단 발표를 하였고 나름 카카오톡 이미지로
신선하게 다가가 처음은 괜찮게 시작하였다고 생각했습니다. 하지만 7분으로 줄이기는 너무 힘들었고 제가 정말 하고 싶었던 저의
가치관 등을 거의 생략하게 되어 아쉬웠지만 여러 사람들 앞에서 발표하고 준비하고 정말 좋은 기회였다고 생각합니다. 그래 두번째주, 세번째주를 걸쳐 배운 CLC Main Workbench 프로그램을 통한 생물정보 분석은 처음에 너무 낯설었고 '과연 내가 해낼 수
있을까'라는 부담이 있었습니다. 하지만 송하나 선배님, 김경윤 주임님, 김경아 선배님에 둘러 쌓인 자리라서
엄청 바쁘신 것을 앉아만 있어도 느낄 수 있었습니다. 그런 와중에도 질문하면 친절하게 잘 설명해주신 덕분에 조금 익숙해지고
압박감에서 벗어 날 수 있었습니다. 정말 감사합니다. 그리고 배우면 배울수록 프로그램이 정말 대단하고 바이오 산업이 급속히 발전
하기위해 꼭 필요한 프로그램이라는 것을 알았습니다. 그리고 매주 금요일 프리젠테이션은 미뤄지기도 했지만 파워포인트 작성 능력과
발표 능력을 키울 수 있는 좋은 기회였습니다. 다른 분야에 가서도 꼭 필요한 교육이라 생각됩니다.
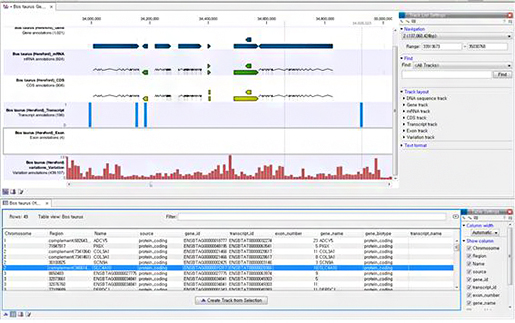
이제 기본기를 다진 후 중요한 CLC Genomics
Workbench 프로그램을 접하게 되었습니다. NGS 포맷을 지원해서 NGS 데이터들을 통합적으로 분석하는 프로그램인 CLC
Genomics Workbench가 지금 이 생물정보 분야에 중요한 저희에게는 잠깐이나마 이 분야을 조금 경험 할 수 있는
기회였습니다. 이 주에는 김경윤 주임님이 내 주신 과제로 저희가 실제로 무언가 분석을 해볼 수 있다는 것이 흥미롭고 좋았습니다.
물론 제가 원하는 결과는 얻지 못하였지만 이 분야에 매력을 느낄 수 있는 좋은 기회였습니다.
저는 분명 이 한 달이 자기소개에서 발표 한 것처럼
제
인생에 정말 중요한 퍼즐 조각이 될 것이라 확신 합니다. 회사에 대한 저의 마음가짐과 잘못된 습관을 고칠 수 있는 계기가 되었고
생물정보학에 대한 눈을 키우게 되었습니다. 한 달동안 저희 4명이 부족해도 이해해 주시고 친절하게 대해주시고 웃어주신 모든분들께 정말 감사합니다. 한 달이 정말 짧은 기간이었던 것 같습니다. 처음 멘토분들과 점심을 먹은 것이 어제 같은데 벌써
한달이 지나가고 이렇게 후기를 쓰게 되었습니다. 이러한 도움이 헛되지 않게 앞으로 이 마음가짐을 잃지 않고 이 한 달의 기억을
잊지 않겠습니다. 마지막으로 한번 더 모든 (주)인실리코젠 직원분들게 감사하다는 말과 함께 후기을 끝내도록 하겠습니다. 모두들 정말 감사 합니다.
제3기 人Co INTERNSHIP 수료생 이용은
학교 수업 중 지도교수님께서 (주)인실리코젠에서 진행하는 人Co INTERNSHIP에 대해 설명 하시고, 참가 희망자를 말하실 때 첫
번째로 손을 들었던 기억이 납니다. 졸업한 몇몇의 선배님들이 다니고 있고, 생물정보를 하는 회사라는 정도만 알고 있었는데, 회사
홈페이지와 블로그를 보면서 사람을 중심으로 하는 고객 맞춤형 서비스업을 중요시 하는걸 알았습니다. 직접적으로 이력서를 작성 하는
것이 처음이라 어떤 내용을 적을까 고민도 해보고 면접을 볼때 어떤 복장과 어떤 말을 해야 좋을까라는 생각을 했었습니다. 시간이
흘러 저에게 전화 한통이 왔는데, 그것은 바로 (주)인실리코젠에서 걸려온 전화였습니다. 서류가 통과 되었으니 면접을 보러오라는
전화였습니다. 면접 당일 파주에서 새벽 기차를 타고 낯선 수원까지 와서 첫 면접을 보려고 하니 매우 긴장되었지만, 입구 게시판에
welcome이라는 글귀 아래 제 이름이 적혀 있는 것을 보고 괜시리 뿌듯했었습니다. 긴장되었지만 면접에서 당당히 준비했던 말들을
모두 하고 만족스런 면접이 그렇게 끝이 났습니다. 최종결과가 있던 날!! 아침 일찍 부터 합격 통보 전화를 기다리고 또 기다리던
찰나에 전화가 걸려왔는데 인턴십 프로그램에 합격 했으니 7월 4일부터 출근 하라는 전화였습니다. 가벼운 발걸음으로 첫 출근을
하던 날 모든 직원 분들께 인사를 드리고 명함을 받았는데 바쁘신 중에도 웃으면서 인사를 받아주시던 (주)인실리코젠의 모든 분들이
아직도 생생히 기억납니다.
1주차에는 사회생활에 필요한 예절교육과, 안전교육,
wiki 사용법 등 교육을 받았고, 2주차 수요세미나 시간에 자기소개 발표가 있으니 준비하라는 얘길 들었습니다. 어떻게 준비해야
나란 사람을 소개할까 생각하면서 발표 준비를 하였고, 드디어 첫 발표를 하던 날 (주)인실리코젠의 모든 직원 분들이 보는 앞에서
발표를 했습니다. 며칠간 발표 연습을 했지만 학교와 다른 분위기에서 첫 발표를 한다는 생각에 떨었습니다. 특히 슬라이드 마지막에
제 이름을 기억해 달라고 했었는데 지금 생각해보면 닭살 돋고 손발이 오글거리는 멘트였습니다.
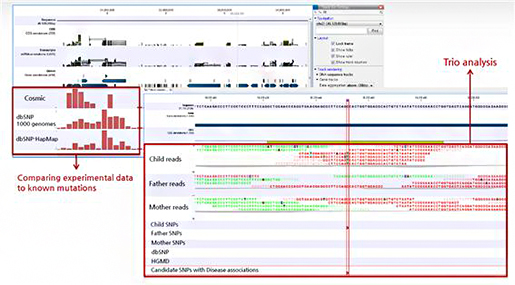
그리고 2주, 3주차에는 본격적으로 분자생물학 데이터
분석 및 관리를 위한 통합 생물정보 분석 툴인 CLC Main Workbench와 NGS 데이터 분석이 가능한 CLC
Genomics Workbench에 대해 배웠습니다. 매주 금요일은 한 주 동안 공부한 것을 파워포인트로 제작하여 발표 했었는데
저에게 자신감도 길러주었고, 다시 한 번 복습 할 수 있는 좋은 시간이었습니다. 어느덧 4주차가 되어 人Co INTERNSHIP이
끝나게 되었지만, 4주 동안의 생활은 앞으로의 생활에 큰 도움이 되었습니다. 평소 아침 잠이 많은 저를 부지런하게 만들어 주었고,
사원의 마음가짐이란 좋은 책을 읽을 수 있는 기회와 여러 교육들을 들으면서 사회생활에서 필요한 예절 및 행동들을 배울 수
있었습니다.
4주의 짧은 시간이었지만 저에게 좋은 말들과 도움을 주셨던 멘토 심재영 주임님을 비롯한 모든 분들에게 감사드리고, 이러한
좋은 추억과 인연을 만들어 주신 최남우 대표님께 감사하단 말 전해드리고 싶습니다.


Posted by 人Co





 입사지원서_2014.docx
입사지원서_2014.docx
 입사지원서.docx
입사지원서.docx
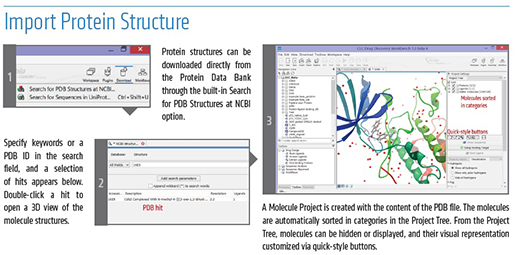
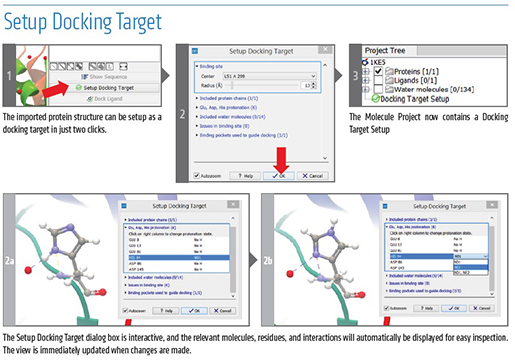
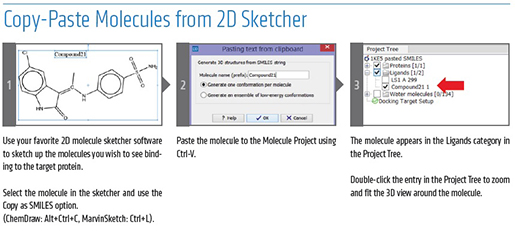
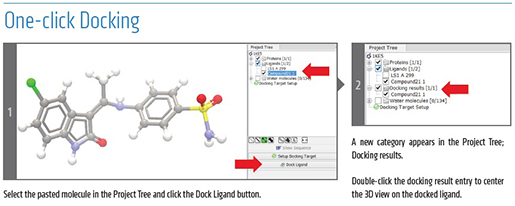
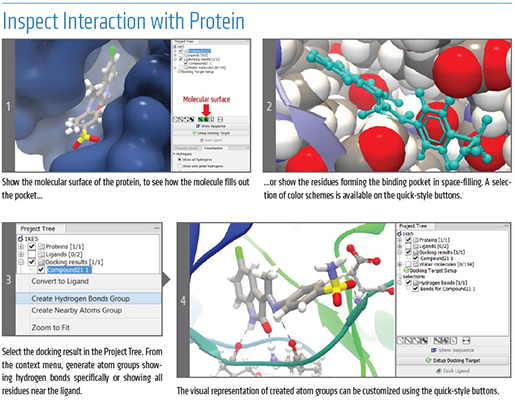

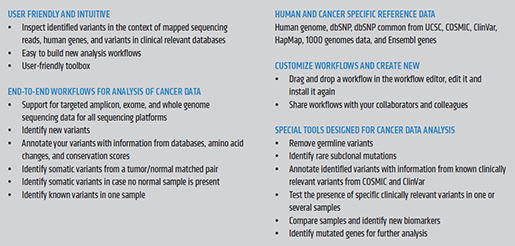
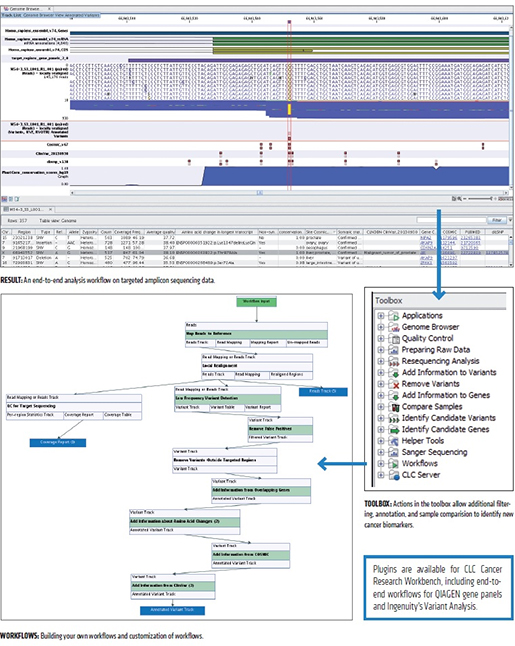
 CLC_DDW_ProductSheet.pdf
CLC_DDW_ProductSheet.pdf