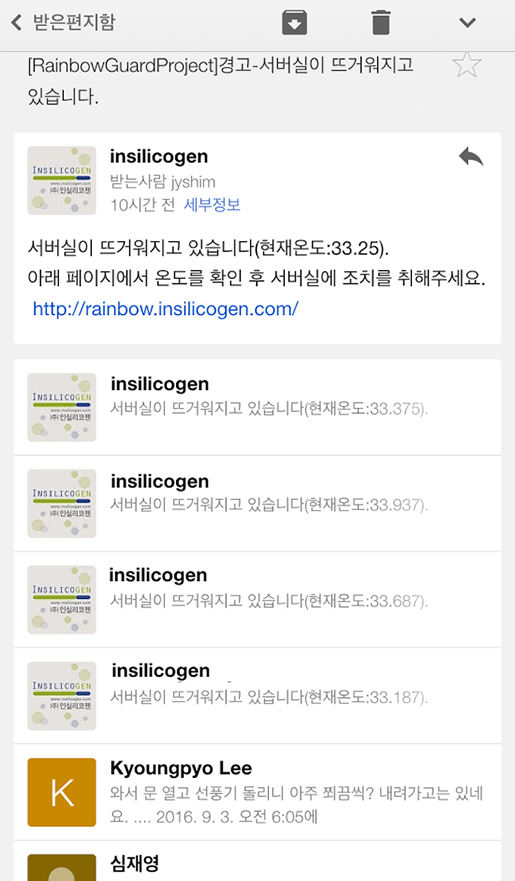
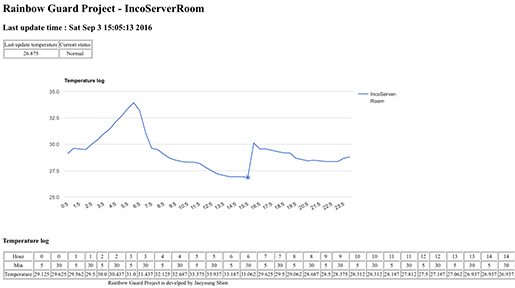
이미지를 이용한 딥러닝의 개요
- Posted at 2020/06/01 19:28
- Filed under 지식관리

최근 여러 분야에서 딥러닝에 대한 관심이 많아지고 있습니다.
생물정보 분야에서는 MRI나 CT 같은 의료 이미지로 학습한 뒤, 질병을 진단하는 연구가 많이 진행되고 있습니다. 그렇다면 이미지를 이용한 딥러닝은 어떤 방식으로 진행될까요?
이미지 딥러닝은 어떠한지 알고 싶어도 코드 위주의 설명이 많아, 코드가 익숙하지 않은 분들은 시작부터 벽이 세워진 느낌이 드셨을 거예요. 코드가 익숙하신 분이시든 그렇지 않은 분이시든 이미지 딥러닝의 입문자분들께 개념 잡는 것에 대해 조금이나마 도움이 되셨으면 하여 알고리즘 개념 설명 위주로 이 글을 준비하였습니다. 그럼 이미지 딥러닝을 하기 위한 알고리즘에 대해 알아보기에 앞서, 컴퓨터는 이미지 파일을 어떤 방식으로 인식하는지에 대해 알아볼까요?

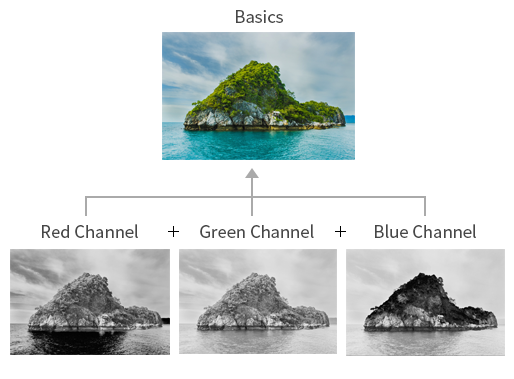
우리가 이미지를 인식하는 방식과 컴퓨터가 이미지를 인식하는 방식은 많이 다릅니다. 우리는 이미지를 눈에 보이는 모습을 그대로 받아들이지만, 컴퓨터의 경우는 숫자로 된 형태로 인식합니다. 숫자는 색의 명암을 나타내며, 0에 가까울수록 어두운색이고 255에 가까울수록 밝은색입니다. 그렇다면 색상은 어떻게 표현할까요? 흑백 이미지의 경우에는 1개의 채널로, 컬러 이미지의 경우엔 RGB(R-Red, G-Green, B-Blue) 3개의 채널로 빨강, 초록, 파란색 각각의 명암을 이용하여 이미지의 색상을 표현합니다.





 [그림 8] Pooling
[그림 8] Pooling


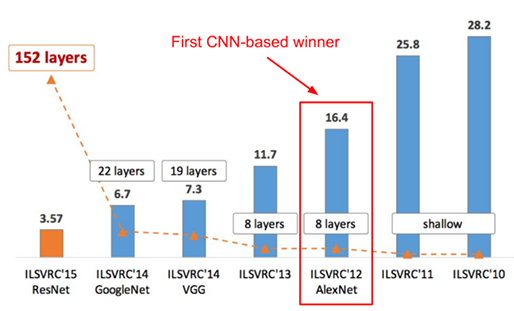
[그림 9] ImageNet
[그림 1] 컬러 이미지의 구조 - Insilicogen (IX Team)
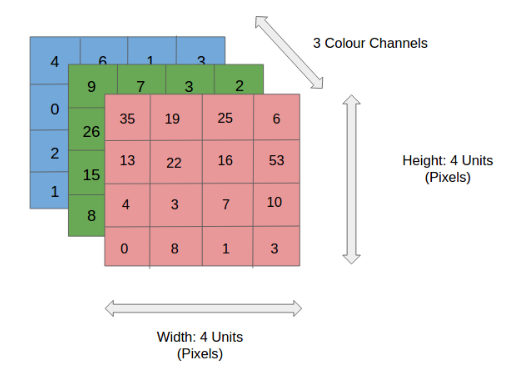
컬러 이미지는 각 픽셀을 채널별로 실수로 표현된 3차원 데이터입니다. 흑백 이미지는 2차원 데이터로, 1개의 채널로만 구성되어 있습니다.
[그림 2] 컬러 이미지의 3차 구조
위의 그림처럼 높이가 4 pixel, 폭이 4 pixel의 이미지일 경우,
컬러 이미지 데이터의 shape은 (4, 4, 3)
흑백 이미지 데이터의 shape은 (4, 4, 1)
로 표현합니다.
컴퓨터가 이미지를 어떤 방식으로 인식하는지에 대해 간단하게 알아봤습니다. 그럼 이제 이미지 딥러닝에선 어떤 알고리즘이 주로 사용되는지 알아볼까요? 딥러닝을 이용하여 이미지를 분류할 때에는 주로 CNN(Convolutional Neural Network) 알고리즘이 많이 사용되고 있습니다. 그렇다면, 이 CNN 알고리즘이 나오기 이전에는 어떻게 학습을 했을까요?
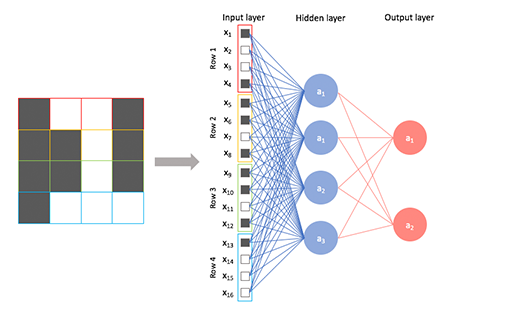
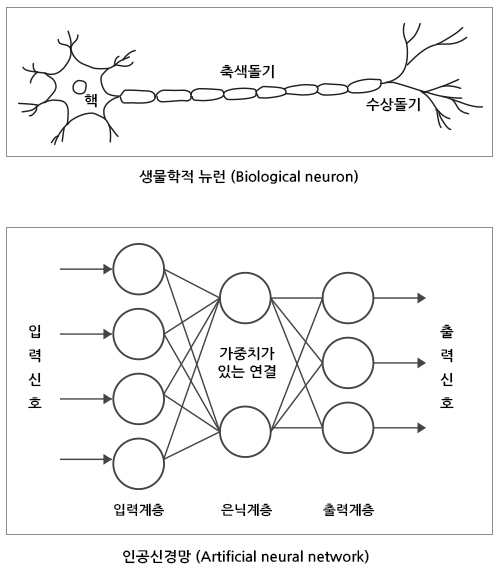
CNN 알고리즘 이전에는 Fully-connected Multi-layered Neural Network의 학습 방식을 이용하여 이미지 딥러닝을 수행했습니다.
[그림 3] Fully-connected Multi-layered Neural Network
형상을 가졌는지에 대해 알 수 없고, 각각의 픽셀을 1차원적으로 보게 됩니다. 이러한 학습 방식으로 인하여 이미지의 크기가 커져서 픽셀의 수가 많아진다거나 은닉층(Hidden layer)의 수가 증가하면 학습시간 및 학습해야 하는 매개변수(Parameter)의 수가 기하급수적으로 증가하게 됩니다. 또한, 이미지가 살짝 회전되었거나 gif처럼 이미지가 움직이는 상태라면 이를 같은 이미지라고 인식하지 못하므로, 조금이라도 변화가 생길 때마다 새로운 입력으로 이미지 데이터를 처리해 주어야 합니다. 그럼 이미지를 분류하기 위해 Fully-connected 학습 방식처럼 이미지의 모든 픽셀이 꼭 중요할까요? 그렇지 않습니다. 이미지의 특성을 찾는 데에 중요하게 작용하는 픽셀이 있지만, 단순히 배경인 부분이라 픽셀 정보를 가지고 있지 않더라도 이미지를 구분하는 데 큰 영향을 주지 않기 때문입니다. 이미지 분류를 하는 데 중요하지 않은 픽셀은 제거하고 학습을 하기 위해 고안된 알고리즘이 바로CNN(Convolutional Neural Network)입니다.
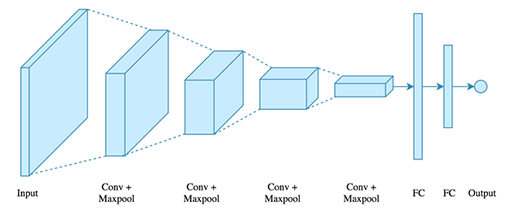
그렇다면 CNN 알고리즘은 어떠한 구조를 이루고 있을까요?
[그림 3] CNN 알고리즘의 구조
CNN은 크게 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나뉩니다. 특징 추출 영역은 합성곱층(Convolution layer)과 풀링층(Pooling layer)을 여러 겹 쌓는 형태(Conv+Maxpool)로 구성되어 있습니다. 그리고 이미지의 클래스를 분류하는 부분은 Fully connected(FC) 학습 방식으로 이미지 분류를 합니다.
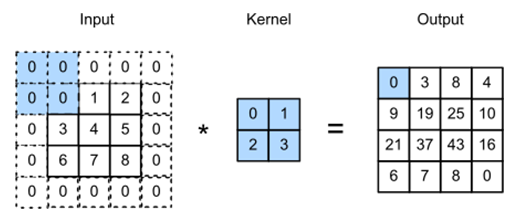
합성곱이란, 주어진 이미지 데이터를 합성곱 필터(Convolution filter)를 통해 이미지 분류에 중요하게 작용할 feature들을 추출하는 데 사용됩니다. CNN 알고리즘 이전에 사용되었던 FC 알고리즘과 달리, 이미지의 형태를 유지하기 때문에 합성곱층을 지나더라도 인접한 픽셀에 대한 정보를 알 수 있습니다. 그렇다면, 합성곱에서 사용되는 합성곱 필터는 무엇일까요? 우선, CNN에서 필터는 커널(Kernel)이라고도 합니다. 필터는 이미지의 공용 매개변수(weight)로 작용하며, 주어진 이미지를 슬라이딩하면서 이미지의 feature들을 찾아냅니다. 여기서 공용 매개변수라고 하는 이유는 합성곱을 진행할 때, 하나의 이미지에 대해서 하나의 필터가 사용되기 때문입니다. 일반적으로 (3, 3)이나 (4, 4)와 같은 정사각 행렬로 정의가 되고, 주어진 이미지를 지정된 간격(Stride)만큼 순회합니다. 그럼 합성곱 필터를 이용하여 합성곱 연산은 어떤 방식으로 진행되는지 알아보기 위해, 아래의 그림으로 설명하겠습니다.
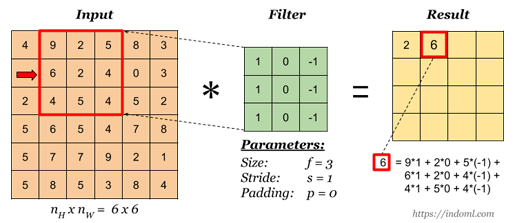
[그림 5] Convolution 연산
위의 그림에서 주어진 이미지 데이터의 크기는 6x6이고, 필터의 크기는 3x3입니다. 이미지를 순회하는 간격(stride)은 1입니다. 연산은 이미지와 필터가 서로 겹쳐지는 부분은 곱을, 각각의 곱은 합하는 방식으로 진행됩니다. 위의 그림에서 Result 아래에 적힌 연산을 참고하시면 이해가 더 쉬우실 거예요.
위의 그림은 합성곱 연산이 진행되는 방식입니다. 이 그림 역시 필터가 이미지를 순회하는 간격은 1입니다. 이처럼 합성곱을 진행하여 얻어진 결과를 피처맵(Feature Map, 위의 그림에서는 오른쪽의 분홍색)을 만듭니다. 여기서 피처맵은 주어진 이미지에서 특징들을 추출한 것이고, 액티베이션맵(Activation Map)이라고도 합니다. 피처맵은 여러 가지의 의미로 사용되지만, 액티베이션맵은 주로 합성곱층의 최종 출력 결과를 의미합니다.
합성곱층에서 필터와 스트라이드의 작용으로 이미지(피처맵)의 크기는 입력 데이터보다 작아지게 됩니다. 그렇다면 합성곱층을 지나면 이미지가 자꾸 줄어드는데, 계속 반복적으로 합성곱층을 지나면 이미지가 없어지지 않을까? 라는 생각이 들게 되죠. 이를 방지하는 방법이 패딩(Padding)입니다. 패딩은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미하고, 보통 0으로 값을 채워 넣습니다.
합성곱층에서 필터와 스트라이드의 작용으로 이미지(피처맵)의 크기는 입력 데이터보다 작아지게 됩니다. 그렇다면 합성곱층을 지나면 이미지가 자꾸 줄어드는데, 계속 반복적으로 합성곱층을 지나면 이미지가 없어지지 않을까? 라는 생각이 들게 되죠. 이를 방지하는 방법이 패딩(Padding)입니다. 패딩은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미하고, 보통 0으로 값을 채워 넣습니다.
위의 그림을 보면, 3x3 이미지의 외각에 0이 채워진 것을 볼 수 있습니다.
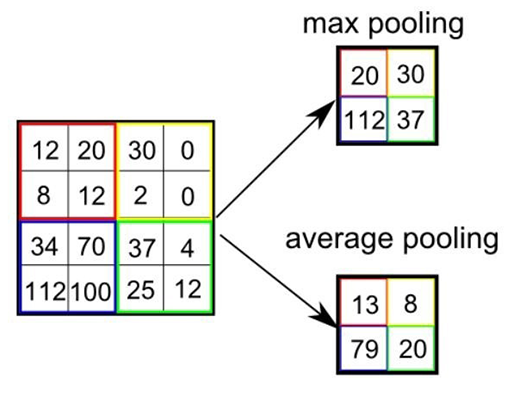
[그림 8] Pooling지금까지 합성곱에 대해서 알아보았습니다. CNN 알고리즘에서 이미지 특징을 추출하는 부분에서 합성곱층 다음으로 나오는 층은 풀링층(Pooling layer)입니다. 합성곱층의 출력 데이터(액티베이션 맵)를 입력으로 받아, 출력 데이터의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용됩니다. 풀링층을 처리하는 방법으로는 Max, Average, Min Pooling이 있습니다. 정사각 행렬의 특정 영역 안에 값의 최댓값, 평균 혹은 최솟값을 구하는 방식이고, 주로 Max Pooling을 사용합니다. 앞의 합성곱처럼 인접한 픽셀값만을 사용한다는 것은 비슷하지만, 합성곱처럼 곱하거나 더하는 연산 과정이 없어서 학습이 필요한 부분이 없고 입력 데이터의 변화에 영향을 적게 받습니다. 이는 최댓값, 평균값, 최솟값 중 하나를 구하는 것이기 때문에, 입력 데이터가 조금 변하더라도 풀링의 결과는 크게 변하지 않습니다.
앞에서 설명해드렸던 바와 같이, CNN은 크게 특징 추출(Feature extraction) 부분과 분류(Classification) 부분으로 나뉩니다. 특징 추출은 합성곱층과 풀링층이 반복적으로 수행되고, 분류는 앞에서 추출된 Feature들이 Fully-connected layer 학습 방식을 이용하여 어떤 이미지인지 분류합니다.
참고) 학습시킬 이미지가 부족하시다면! 이미지 학습을 위한 open data source
이미지 분류하기 위해 이미지를 학습시킬 때, 하나의 클래스(ex. 강아지 클래스, 고양이 클래스)당 최소 1,000장이 필요합니다. 학습을 많이 시키면 많이 시킬수록 이미지를 분류하는 정확도는 당연히 올라갑니다. 그렇다면, 이미지 학습을 하기 위해서 많은 양의 이미지 데이터가 필요하겠죠? 딥러닝이 활성화되면서 공개 이미지를 수집하는 데이터베이스가 많아졌고, 대표적으로 ImageNet과 Kaggle 등이 있습니다. 이미지를 학습하는 데 필요한 이미지 데이터를 공개적으로 제공하는 사이트이므로, 아래 사이트를 들어가시면 이미지 딥러닝 활용에 여러 방면으로 도움이 될 것입니다. :)
[그림 9] ImageNet

(https://www.kaggle.com/)


CNN 알고리즘에 대해서 더 자세하게 설명해 드리고 싶었지만, 그러면 본 취지에 맞지 않을 것 같았어요. 제가 생각하기에 이미지 딥러닝의 입문자분들께 가장 필요한 부분 위주로 이 글을 작성하였습니다. 이 글에 적힌 것들을 바탕으로 궁금한 부분이 생길 때마다 조금씩 조금씩 자료를 찾다 보면, 깨닫지 못한 사이에 이미지 딥러닝에 대해 많이 알게 되실 거예요. 조금이나마 도움이 되셨길 바라며, 너무 두려워하지 마시고 힘내시길 바랍니다. :D
Posted by 人Co
- Tag
- CNN, insilicogen, 딥러닝, 인실리코젠
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/346






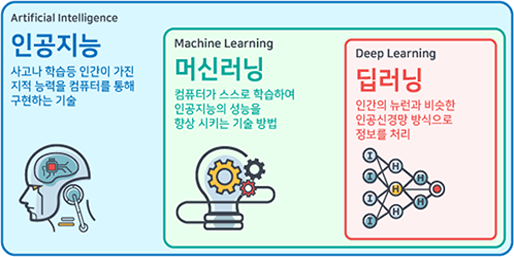


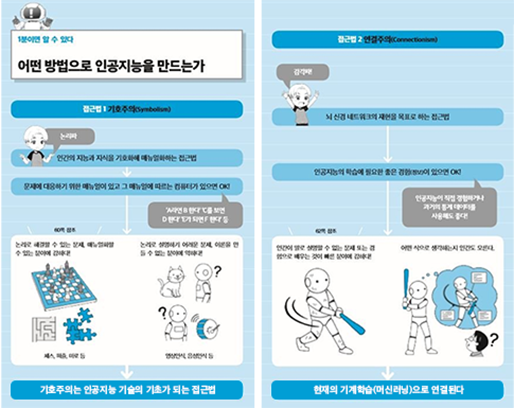
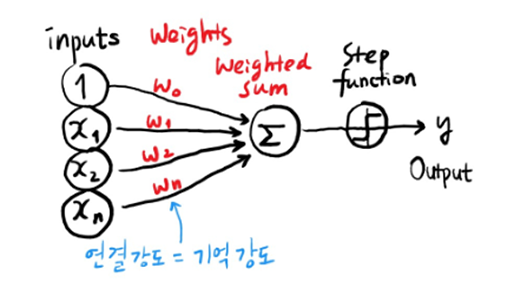
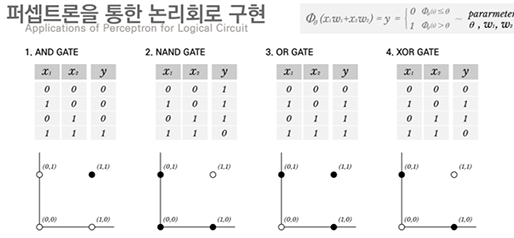
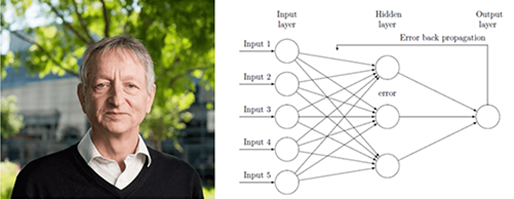









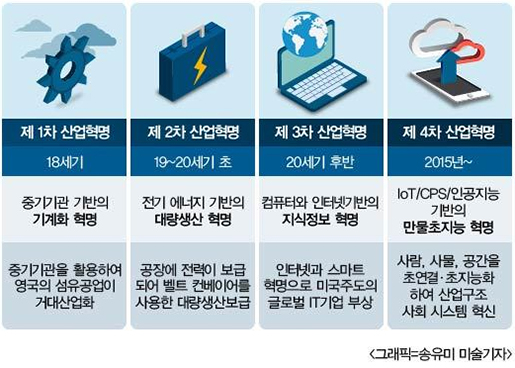
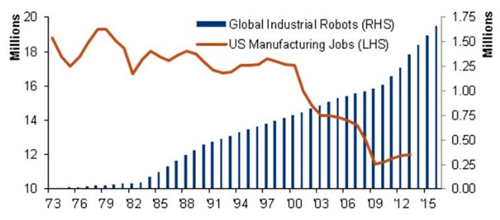
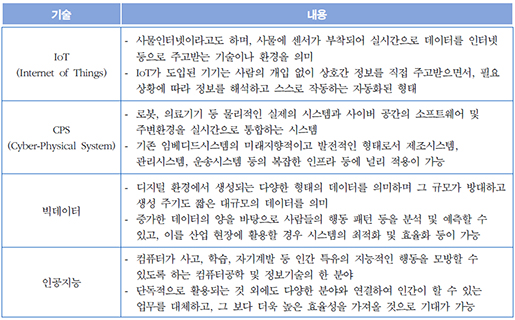 <출처 : 해외 ICT R&D 정책 동향, 정보통신기술진흥센터(2016)>
<출처 : 해외 ICT R&D 정책 동향, 정보통신기술진흥센터(2016)>
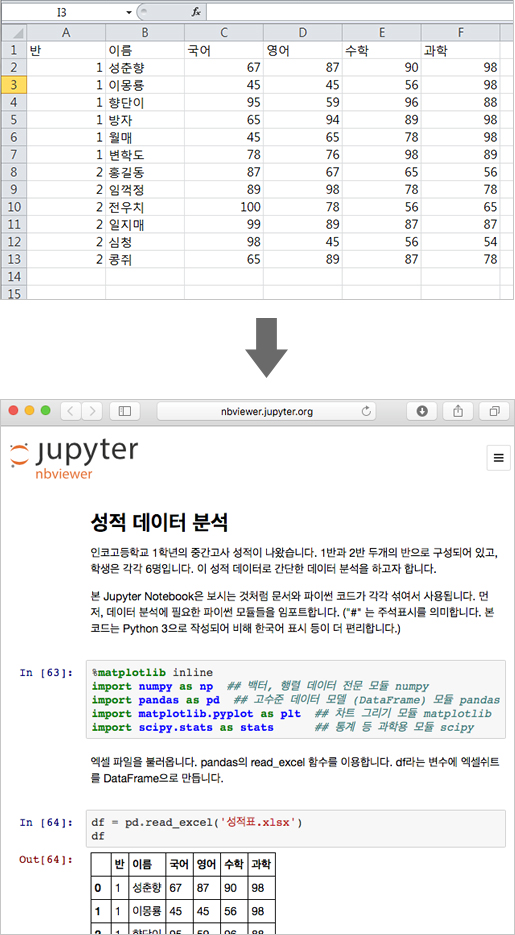
 성적표.xlsx
성적표.xlsx