
[Quipu Issue Paper] Epigenomics Ⅱ - ChIP-seq
- Posted at 2010/03/12 08:18
- Filed under 생물정보
연재 순서
1. Assembly
2. Variation study
3. Expression study
4. Epigenomics
5. Genome Annotation
6. Next Generation Bioinformatics
7. Data Management for web 2.0 Era
8. Semantic Network for Integrated Biology Data
9. Gene Network Discovery by Text-mining
10. Centralization for High-throughput Data Analysis
이번주 연재에서는 Next Generation Sequencing의 세 번째 Application인 Epigenomics 중에 단백질에 binding된 DNA 서열을 분리하여 NGS 방식의 시퀀싱을 통해 binding site를 동정하는 방법인 CHIP-Seq 분석 방법에 대해 알아보겠습니다.
2-3-2. ChIP-seq
CHIP(chromatin-immunoprecipitation)은 특정 유전체 영역에 binding 하는 히스톤이나 전사 인자(Transcription Factors, TFs)와 같이 특정 DNA서열에 binding 하는 단백질과 genomic fragments를 분리하기 위해 많이 응용 되어 왔다. 이 기술은 빠르게 발전하여 large-scale의 TF-DNA interactions 혹은 chromatin packaging (histone modification을 통한 genomic DNA와의 packaging) 연구에 중심 기술로 자리 잡았다. CHIP-Seq은 기존의 CHIP-chip에서 보여 지던 해상도의 한계와 chip에 올려 진 프로브에 대한 한계를 극복하는 방법으로 단백질에 binding된 DNA 서열을 분리하여 NGS 방식의 시퀀싱 통해 binding site를 동정하는 방법으로 발전하였다(그림 3). 그 결과 genome wide epigenetic study가 가능하게 되었다.
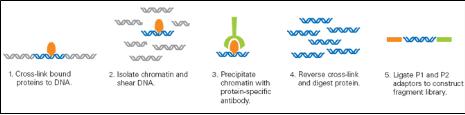
Genomic DNA와 특정 단백질의 binding 후 단백질 specific antibody를 이용하여
분리한다. 이후 단백질을 제거하고 NGS 기술을 이용하여 시퀀싱 한다[5].
분리한다. 이후 단백질을 제거하고 NGS 기술을 이용하여 시퀀싱 한다[5].
CHIP-seq은 실험적으로 짧은 DNA 절편에 binding하는 특성 때문에 non-specific binding complex의 background 처리가 반드시 필요하다. 이를 해결하기 위해 실험적으로는 antibody 만을 사용한 대조군을 설정하여 비교하는 방법과, 통계학적으로는 주어진 단백질이 주어진 위치에 정확하게 binding 할 확률을 계산하도록 하는 것이다. 이때 genome 전체 서열(g)에 주어진 서열(t)이 정확하게 mapping될 확률은 t/g로 포아송 분포 (poisson distribution) 혹은 negative binomial distribution을 이용하여 추정하게 된다[3].
이후 consensus binding sequence를 도출하게 되면 이를 데이터베이스로 하여 다른 종의 분석에 이용할 수 있게 된다. 이렇게 TF와 그에 관련된 정보로 전문화 하여 구축된 데이터베이스 중 거의 유일한 곳이 BIOBASE의 TRANSFAC이다(그림4)[6].
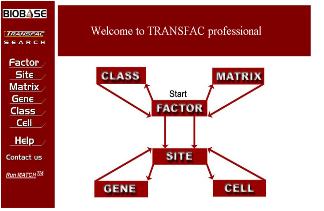 그림 4. TRANSFAC.
그림 4. TRANSFAC.
Transcription factor와 binding site 및 관련
pathway정보를 담고 있는 유일한 TF database.
이후 consensus binding sequence를 도출하게 되면 이를 데이터베이스로 하여 다른 종의 분석에 이용할 수 있게 된다. 이렇게 TF와 그에 관련된 정보로 전문화 하여 구축된 데이터베이스 중 거의 유일한 곳이 BIOBASE의 TRANSFAC이다(그림4)[6].
Transcription factor와 binding site 및 관련
pathway정보를 담고 있는 유일한 TF database.
TRANSFAC은 genome내의 유전자 upstream 분석에 기초 자료를 제공하여 유전자 조절 메카니즘 분석에 필수적으로 이용되고 있다. 실험적으로 검증된 TF의 정보를 manual curation을 통해 고품질의 데이터를 쌓아가고 있으며, 그간 CHIP-chip 방식의 데이터로 밝혀지던 정보들이 CHIP-seq 방식의 데이터로 전환 되면서 더욱 빠르게 진행되고 있어 이를 이용한 BIOBASE의 데이터베이스 또한 더욱 빠르게 쌓여갈 것으로 예상된다. 뿐만 아니라 이미 human의 경우 모든 유전자의 upstream을 분석하여 binding 가능한 TF를 제공하고 있으며, 이를 이용한 pathway 분석에도 많은 데이터와 분석 프로그램을 제공하고 있다. 그중 TRANSPATH는 affymatrix data를 이용한 발현 분석 시 DEGs의 pathway를 분석하는데 해당 유전자의 upstream에 존재하는 TFs와 관련 pathway를 분석하여 세포내 전체적인 유전자의 기능을 살펴볼 수 있도록 하였다[6].
이러한 CHIP-Seq은 다양한 플랫폼에서 분석이 가능한 가운데, CLC NGS Cell을 이용하여 assembly를 진행하게 되면 genbank 형식의 ‘.gbk' 파일을 reference로 사용하여 GUI 형태로 유전체 전체의 분포를 확인할 수 있어 데이터 해석의 용이함을 얻을 수 있다(1-2. Assemble 참조). 또한 비슷하게 Illumina의 Genome Analyzer의 경우 ChIP-seq 분석을 통해 얻어진 작은 서열들을 ELAND를 이용하여 유전체에 정렬하게 되고 그 결과는 UCSC genome browser를 통해 유전체 내의 위치와 분포를 확인할 수 있다(그림 5).
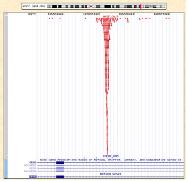 그림 5. UCSC genome browser를 통한 TF binding site의 유전체 내 위치 확인.
그림 5. UCSC genome browser를 통한 TF binding site의 유전체 내 위치 확인.
붉은색으로 정렬된 바는 NGS로 시퀀싱 되어진 reads로
유전체와의 reference assemble를 통해 위치를 확인한다.[4]
다음 연재에서는 약 2주에 걸쳐 유전체 내의 유전자 위치와 기능을 해독하는 과정인 genome annotation에 대해 알아보겠습니다.
많은 관심 부탁드립니다.
참고문헌
1. Horner DS, Pavesi G, Castrignanò T, De Meo PD, Liuni S, Sammeth M, Picardi E, Pesole G. (2009) Bioinformatics approaches for genomics and post genomics applications of next-generation sequencing. Brief Bioinform. [Epub ahead of print]
2. Weber M, Schubeler D. (2007) Genomic patterns of DNA methylation: targets and function of an epigenetic mark. Curr Opin Cell Biol. 19, 273-80
3. Roch 454 : Applications - Epigenetics
(http://www.454.com/applications/ChIP-seq-methylation-epigenetics.asp)
4. Illumina : Applications - Gene Regulation and Epigenetic Analysis
(http://www.illumina.com/applications.ilmn#dna_protein_interaction_analysis_chip_seq)
5. Appied Biosystems : Applications & Technologies - The SOLiD System
(http://www3.appliedbiosystems.com/AB_Home/applicationstechnologies/SOLiD-System-Sequencing-A/index.htm)
6. Kel, A., Voss, N., Jauregui, R., Kel-Margoulis, O. and Wingender, E. (2006) Beyond microarrays: Find key transcription factors controlling signal transduction pathways BMC Bioinformatics. 7, S13
이러한 CHIP-Seq은 다양한 플랫폼에서 분석이 가능한 가운데, CLC NGS Cell을 이용하여 assembly를 진행하게 되면 genbank 형식의 ‘.gbk' 파일을 reference로 사용하여 GUI 형태로 유전체 전체의 분포를 확인할 수 있어 데이터 해석의 용이함을 얻을 수 있다(1-2. Assemble 참조). 또한 비슷하게 Illumina의 Genome Analyzer의 경우 ChIP-seq 분석을 통해 얻어진 작은 서열들을 ELAND를 이용하여 유전체에 정렬하게 되고 그 결과는 UCSC genome browser를 통해 유전체 내의 위치와 분포를 확인할 수 있다(그림 5).
붉은색으로 정렬된 바는 NGS로 시퀀싱 되어진 reads로
유전체와의 reference assemble를 통해 위치를 확인한다.[4]
다음 연재에서는 약 2주에 걸쳐 유전체 내의 유전자 위치와 기능을 해독하는 과정인 genome annotation에 대해 알아보겠습니다.
많은 관심 부탁드립니다.
참고문헌
1. Horner DS, Pavesi G, Castrignanò T, De Meo PD, Liuni S, Sammeth M, Picardi E, Pesole G. (2009) Bioinformatics approaches for genomics and post genomics applications of next-generation sequencing. Brief Bioinform. [Epub ahead of print]
2. Weber M, Schubeler D. (2007) Genomic patterns of DNA methylation: targets and function of an epigenetic mark. Curr Opin Cell Biol. 19, 273-80
3. Roch 454 : Applications - Epigenetics
(http://www.454.com/applications/ChIP-seq-methylation-epigenetics.asp)
4. Illumina : Applications - Gene Regulation and Epigenetic Analysis
(http://www.illumina.com/applications.ilmn#dna_protein_interaction_analysis_chip_seq)
5. Appied Biosystems : Applications & Technologies - The SOLiD System
(http://www3.appliedbiosystems.com/AB_Home/applicationstechnologies/SOLiD-System-Sequencing-A/index.htm)
6. Kel, A., Voss, N., Jauregui, R., Kel-Margoulis, O. and Wingender, E. (2006) Beyond microarrays: Find key transcription factors controlling signal transduction pathways BMC Bioinformatics. 7, S13
Posted by 人Co
- Tag
- annotation, Assembly, binding, BIOBASE, CHIP-Seq, Illumina, insilicogen, NGS, pathway, TRANSPATH, TRASFAC, UCSC genome browser, upstream, 인실리코젠, 전사인자
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/56
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

