
2015년 (주)인실리코젠 송년회 후기!
- Posted at 2015/12/29 16:26
- Filed under 회사소식
人Co의 2015년도를 한마디로 표현해 보자면 다사다난 이라는 말이 적절할 것 같습니다. 생물정보 전문기업이라는 비전을 제시하고 있는 人Co가 기존에 수행하고 있는 생물정보 분석/컨설팅, SW판매/컨설팅 및 용역사업, 연구과제들을 수행하는 반면 시대흐름에 맞춰 새로운 비지니스 모델을 발굴하기 위해 힘겨운 병행을 하였습니다. 그런 가운데 人Co인들이 협력하여 새로운 비지니스 모델도 어느 정도 윤곽이 드러나고 있고, 수행했던 모든 사업들도 성공적으로 마무리하여 오늘... 12월 18일, 얼마전에 개소식을 마친 人CoFLEX에서 2015년도 송년회를 개최하였습니다.

올해 송년회의 사회는 2015년 7월에 人Co에 합류하신 이지현 주임님께서 맡아주셨습니다. 좌중을 압도하는 특출한 말솜씨를 앞세워 송년회 분위기를 한껏 띄워주셨습니다.

송년회의 첫번째 순서는 프로젝트 리뷰였습니다. 올해 각 팀별로 수행한 사업의 성과를 팀장이나 팀원이 발표하고 그 가치를 공유하고, 서로의 노고에 박수를 쳐주기 위한 자리였습니다. 슬라이드 하나하나를 보면서 들을때마다 완벽하지 않은 환경속에서도 사업의 성공적인 마무리를 위해 애쓰신 흔적이 역력하였습니다.

DX팀, Consulting팀, Convergence팀, Descign팀, 리서치실, 솔루션그룹, 대전지사, 시맨틱스그룹, MD협의회 모두모두 수고 많으셨습니다.

다음으로 사장님의 송년사가 이어졌습니다. 매 행사때마다 좋은 말씀 많이 해주시는데, 오늘 송년사의 키워드는 협력이었습니다. 강조하신 문구를 적어보면...

다음 순서는 선물교환 순서였습니다. 직원들이 각자 1만원 상당의 선물을 준비하여 자신이 뽑은 사람에게 선물을 주고 덕담한마디씩 해주는 시간을 가졌습니다.
제가 기억에 남는 선물은 조관희 팀장님의 지푸드 식권이었습니다. 선물도 주고받고 덕담도 주고받고... 모두들 즐거웠던 선물교환 행사였던 것 같습니다.

올해 송년회의 사회는 2015년 7월에 人Co에 합류하신 이지현 주임님께서 맡아주셨습니다. 좌중을 압도하는 특출한 말솜씨를 앞세워 송년회 분위기를 한껏 띄워주셨습니다.
송년회의 첫번째 순서는 프로젝트 리뷰였습니다. 올해 각 팀별로 수행한 사업의 성과를 팀장이나 팀원이 발표하고 그 가치를 공유하고, 서로의 노고에 박수를 쳐주기 위한 자리였습니다. 슬라이드 하나하나를 보면서 들을때마다 완벽하지 않은 환경속에서도 사업의 성공적인 마무리를 위해 애쓰신 흔적이 역력하였습니다.
DX팀, Consulting팀, Convergence팀, Descign팀, 리서치실, 솔루션그룹, 대전지사, 시맨틱스그룹, MD협의회 모두모두 수고 많으셨습니다.
다음으로 사장님의 송년사가 이어졌습니다. 매 행사때마다 좋은 말씀 많이 해주시는데, 오늘 송년사의 키워드는 협력이었습니다. 강조하신 문구를 적어보면...
여러 사람들이 다르지만, 모두 연결되어 있고, 다르기 때문에 매력을 느낄수 있다. 역사적으로 보았을 때 동일하게 반복되어져 온 사실이고, 이 다름과 연결속에서 성장이 있었고 발전이 있었다. 그 과정을 겪으면서 사람과 집단이 성장할 수 있으니, 그렇기 때문에 협력을 하는 것이 중요하다.
다음 순서는 선물교환 순서였습니다. 직원들이 각자 1만원 상당의 선물을 준비하여 자신이 뽑은 사람에게 선물을 주고 덕담한마디씩 해주는 시간을 가졌습니다.
제가 기억에 남는 선물은 조관희 팀장님의 지푸드 식권이었습니다. 선물도 주고받고 덕담도 주고받고... 모두들 즐거웠던 선물교환 행사였던 것 같습니다.
다음 순서는 영화관람이었습니다. 특별히 이번 영화관람은 극장에 가지않고 人CoFLEX에서 자유롭게 식사하면서 영화관람을 했습니다. 편하게 식사하면서 영화도 볼 수 있는 人CoFLEX... 이제 극장 갈 필요 없을 것 같네요... ^^
마지막 순서는 전체 회식이었습니다. 영화 보면서 든든히 배도 채웠겠다... 회사 근처 세계맥주전문점에서 2015년도 마지막 회포를 풀었습니다.
이후에도 2차 회식자리를 마련하여 올해의 마지막을 활활 불태웠습니다. 저에게는 올해 송년회가 벌써 10번째 행사였습니다. 10년 세월을 돌아보니 처음 입사했을때 5명이었던 인원이 지금은 40명이 넘는 튼실한 강소기업으로 자리 잡은 느낌입니다. 저의 작은 바램이 있다면, 오늘 송년회 자리에 참석하여 희노애락을 함께 나누었던 人Co들이 10년, 20년, 앞으로도 쭈~~~욱 오늘과 같은 날을 계속 맞이했으면 좋겠습니다.
작성자 : 경영지원실 박병준 선임
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/196

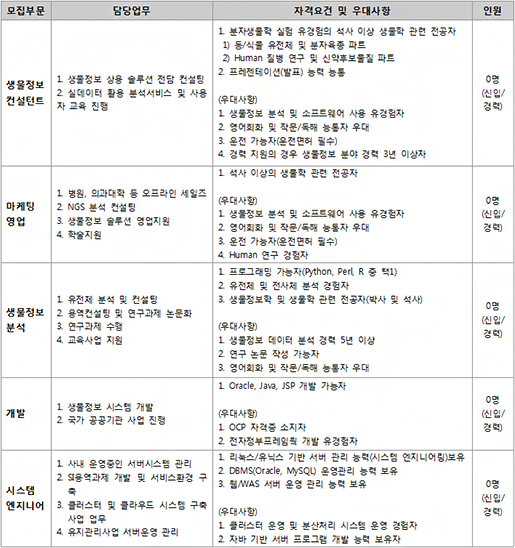
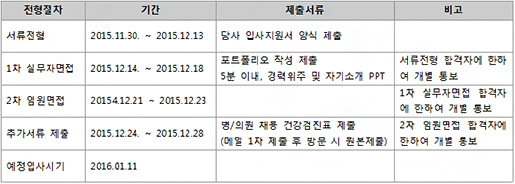 ※
※  입사지원서_성명_지원부문.docx
입사지원서_성명_지원부문.docx

















