
바이오빅데이터의 작은 이야기
- Posted at 2013/08/28 10:44
- Filed under 생물정보
1. 개요
최근 들어 빅데이터가 상당히 큰 이슈가 되고 있다.
박근혜 정부의 가장 큰 흐름 중 하나가 빅데이터라는 이야기를 쉽게 접할 수 있는 상황이다. 신문지상에서도 큰 주제로 빅데이터에 관한
기사가 연일 연제가 되고 있으며, 정부가 새롭게 추진하는 사업에서도 빅데이터라는 키워드가 핵심 이슈로 자리 잡고 있다. 최근
8월 8일자 세계일보에서 “심야버스 노선정책 지원”, “국민건강 주의 예보 서비스, 의약품 안전성 조기경보 서비스, 심실 부정맥
예측 등 보건의료 서비스, 소상공인 창업성공률 제고를 위한 점포이력 분석서비스 등을 주요 시범사업으로 정리한 것을 볼 수 있다.
그러나 빅데이터에 대해서 이름을 알고 간략한 개념을 알고 있었을 뿐 어떻게 현재 바이오데이터에 접목할 수 있는지 현재 상황은
어떠한지 파악하기가 쉽지 않았다. 일반적으로 전산의 다양한 알고리즘들이 바이오분야에 뒤늦게 접목되는 것처럼 아직 바이오데이터를
빅데이터로 접목하는 것은 시기상조일 것이라는 생각이 컸었던 것이 사실이다. 빅데이터의 시대, 바이오분야에서는 어떠한 흐름이
있으며, 어떻게 준비해야 되는지 좀 더 구체적으로 준비를 해야 될 시기가 된 것 같다.
‘데이터 data’라는 말은 라틴어로 ‘사실 fact’로서 ‘주어진다 given’는 뜻이다. 오늘날 데이터는 기록되거나 분석되거나 재정리할 수 있는 어떤 것을 가리킨다. 또한 어떤 현상을 ‘데이터화’한다고 하는 것은 표를 만들고 분석이 가능하도록 그 현상을 수량화된 형태로 만든다는 뜻이다. 따라서, 우리가 쉽게 혼동하는 데이터화와 디지털화는 서로 아주 다른 개념이다. 디지털화란 아날로그 정보를 컴퓨터가 처리할 수 있도록 2진법 코드의 0과 1로 만든다는 뜻이다.
15세기 중엽 인쇄기 발명 이후 약 1억 3천만 권의 고유한 책이 출판된 것으로 추산된다. 구글은 세계의 문헌을 데이터화하기 위해서 문헌 자료를 스캔하기 시작하여 2012년까지 2천만권 이상의 문헌을 스캔하였다. 이는 글로 된 세계 유산의 15퍼센트 이상에 해당하는 막대한 양이다. 이로 인해 ‘컬처로믹스(Culturomics)’라고 하는 새로운 학문 분야가 생겨났다. 텍스트의 양적 분석을 통해 인간 행동과 문화 트랜드를 이해하는 컴퓨터 어휘학이 그것이다.
위에서 데이터를 정의한 것처럼 빅데이터를 정의하는 말은 다양하다. 단어 때문에 단순히 양이 많은 데이터라는 것을 먼저 떠올리게 되는데 데이터의 양이라는 것은 빅데이터의 한 측면일 뿐이다. 빅데이터의 가장 많이 알려진 특성은 다음처럼 V로 시작하는 세 가지 키워드로 표시할 수 있다.
• Variety : 다양한 데이터 (구조화 데이터 + 비구조화 데이터)
• Velocity : 데이터 발생 빈도, 갱신 빈도 (1초에 수십 건 이상)
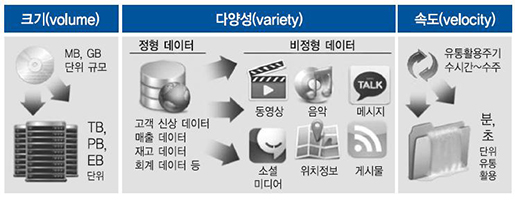
하지만 빅데이터를 단순히 위 3가지의 특성만으로 정의하기에는 부족한 점이 많다. 따라서 보다
광범위한 의미의 빅데이터란 위에서 언급한 ‘3V (데이터양/다양성/속도) 측면에서 관리가 곤란한 데이터 및 그 데이터를 축적,
처리, 분석할 수 있는 기술, 나아가 그 데이터를 분석해서 유용한 의미와 통찰을 이끌어낼 수 있는 인재와 조직을 포함하는 포괄적인
’개념‘이다. 빅데이터를 정의하는데 있어 관련 사례를 제시하는 것이 좀 더 쉽게 와 닿을 수 있는데, 구글은 월간 900억 회에
이르는 인터넷 검색을 위해 매월 600 페타바이트의 데이터를 처리한다고 한다. 또한 트위터의 경우 하루에 8 테라바이트나 되는
데이터를 생성하고, 페이스북은 매달 300억 개나 되는 콘텐츠를 생산해 내는데 그 양이 30 페타바이트 이상이라고 한다. 전혀
감이 잡히지 않는 어마어마한 수치인 것이다.
전산학자는 아니지만 생물의 데이터를 다루고 있는
생물정보전문가로서 바이오정보(유전체 데이터)의 규모가 상당하다고 생각을 했었는데 현재 실제로 생성되고 분석 및 서비스에 활용되고
있는 외국의 사례를 알게 되니 크게 놀라지 않을 수 없었다.
노무현 전 대통령은 국정 운영에 국민의 참여를 중요시하는 참여정부를 이슈로 하여 공공기관의 전자정부화를 적극 추진하였다. 그로 인해 문서화 되어있는 많은 공공기관의 업무들이 전자화, 전산화되어 이를 현재까지도 잘 운영하고 있어, 세계적으로 우수한 전자정부를 갖추고 있다.
현재는 미국 연방정부를 비롯하여, 영국 정부 등 서유럽 국가에서는 열린 정부 정책을 추진하고 있다. 즉 정부나 지자체 등 공공 기관이 보유한 통계 자료, 지리정보, 생명 과학 등의 과학 데이터를 공개하고 이를 모두 연결해 사회 전체가 큰 가치를 만들어내고 공유하려는 움직임을 구축해 나가고 있는 것이다. 이는 WWW (World Wide Web)의 구조를 고안하여 ‘WWW의 아버지’로 불리는 영국의 컴퓨터 과학자인 팀 버너스-리는 미국 캘리포니아주 롱비치에서 ‘TED (Technology Entertainment Design)’ 콘퍼런스에서 ‘Raw Data Now!’라고 호소한 바 있다. 이러한 움직임을 ‘LOD (Linked Open Data)라고 부른다.
미국 연방정부는 오바마 대통령이 ‘투명하고 열린 정부’를 표방하여 ‘투명성’, ‘국민참여’, ‘정부 및 민간 연계 및 협업’을 세 가지 큰 원칙으로 삼고 투명하고 시민에게 열린 협조적 정부가 될 것을 각 정부 기관에 요구했다고 한다. 이 3원칙 중 ‘투명성’을 구현한 것이 국제 정세, 환경, 경제 상황등 연방정부 기관이 보유한 각종 데이터를 시민에게 제공하는 웹 사이트 ‘Data.gov’이다. Data.gov에서는 정부 데이터가 국민의 자산이라는 사고 방식을 바탕으로 연방정부 기관이 소유한 Raw Data Catalog와 지역별 데이터 Geo Data Catalog를 카탈로그 형식으로 제공한다. 덕분에 2009년 5월 47개 데이터에 불과했던 카탈로그는 2012년 5월 시점에서는 39만개 까지 확대되었다고 한다.
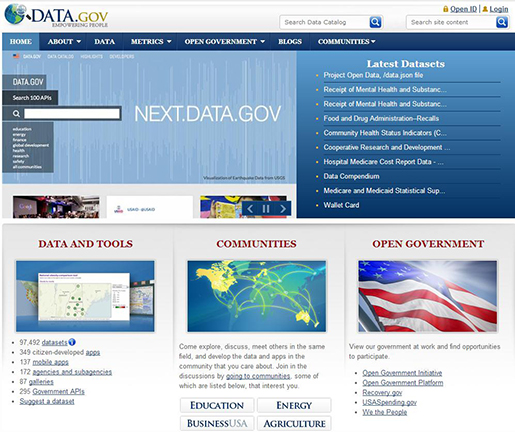
영국 정부 또한 2010년 1월부터 정부 소유의 데이터를 모은 ‘Data.gov.uk’를 구축, 이를 공개하여 일반 시민이 범죄, 교통, 교육 등 개인 데이터 이외의 정부 소유 데이터에 접근할 수 있도록 하었다. 공개 직후부터 2,500개의 많은 데이터가 공개되었고, 2012년 5월 시점에 8,400개 이상이 되어 프로젝트가 시작한지 2년 만에 3배 이상 증가하였다.

우리 정부 또한 국가의 다양한 정보를 공개하여 이를 국민의 생활에 유익한 형태로 서비스하고자 하는 정책들이 지속적으로 개발되고 있는 것을 확인할 수 있다. 또 한 정부 뿐만 아니라 정부가 공개한 데이터를 이용하여 상용 서비스를 제공하는 벤처 기업도 속속 등장하고 있어, 이제는 멜론과 같이 음악 스트리밍 사이트에서 온라인 음악을 구매하는 것처럼 정부의 다양한 정보들을 손쉽게 원하는 형태로 구매하여 빅데이터에 활용할 수 있는 시대가 된 것이다.
4. 바이오회사의 빅데이터 시도
빅 데이터 회사들은 제공하는 가치에 따라 세 종류로 나눌 수 있다. 그 가치는 각각 데이터, 기술, 아이디어다.
첫 번째 가치인 데이터 기업들은 데이터를 보유하고
있거나 최소한 데이터에 접근할 수 있는 회사들이다. 이들의 사업 목적은 데이터 자체가 이닐 것이다. 또는 데이터에서 가치를
추출하는 데 필요한 기술이나 창의적 아이디어가 없을 수도 있다. 가장 좋은 예가 트위터인데, 트위터 서버에는 엄청난 양의 데이터가
넘쳐나지만, 트위터는 다른 이들이 이것을 이용할 수 있도록 두 개의 독립적 회사를 통해 데이터 사용을 허가하고 있다.
두 번째 가치는 기술이다. 기술 기업에는 자문 회사나
기술 판매사, 분석 제공 업체 등이 포함될 것이다. 이들은 전문성을 가지고 일하지만 스스로 데이터를 보유하거나 데이터에서 가장
혁신적인 용도를 생각해낼 창의성이 없을 수도 있다.
세 번째 가치는 아이디어, 즉 빅데이터 사고방식이다.
어떤 회사들은 성공의 주된 원인이 데이터나 노하우에 있지 않다. 이들 기업이 두각을 나타내는 것은 설립자나 직원들이 데이터에서
새로운 형태의 가치를 추출할 수 있는 독창적인 아이디어를 보유하고 있기 때문이다.
다양한 분야에서 빅데이터를 이용하여 인간이 원하는
결과를 얻고자 하는 사례들이 끊임없이 전해지고 있다. 미국과 유럽의 경우 이러한 빅데이터에 대한 선점효과를 톡톡히 누리고 있는데,
조만간 바이오 분야의 거대 빅데이터를 선점하는 회사들을 곧 접하게 될 것이다. 우리 회사와 협력을 맺고 있는 해외 파트너사들도
이에 대한 사업 전략을 수정하여 적극적으로 추진하는 것을 확인해 볼 수 있다.
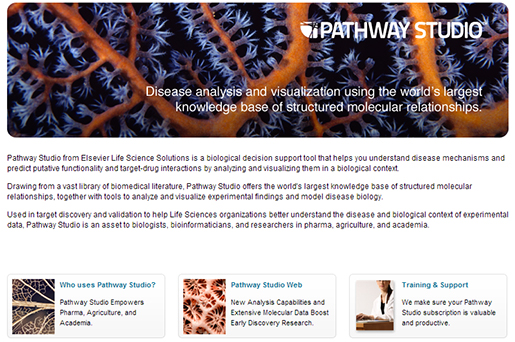
거대 저널 회사인 Elsevier는 매년 출간하는 저널의 수만 1천여 종이 넘는다고 하며, 전 세계 저널의 40% 가량을 독점하고 있으나, 독과점방지법으로 인해 표면상으로는 25% 정도의 시장을 장악하고 있다고 알려져 있다. 이 수치도 엄청난 수치인 것이다. 전 세계의 전문화되고 검증된 정보의 25%를 독점적으로 관리하고 보유하고 있다는 것은 엄청난 가치를 보유하고 있는 셈이다. Elsevier는 단순히 저널을 배포하고 관리하는 회사에서 자체적으로 보유하고 있는 지식정보를 이용하여 공격적으로 새로운 가치를 추출하는 사업을 추진하고 있다. 즉 텍스트마이닝이라는 기술을 통해서 전문화된 문헌 속에서 질병과 현상, 그리고 유전자 및 관련 약물의 상호 연관관계를 추출하여 새로운 약물 개발 및 질병 진단과 예방, 처리에 새로운 사업 모델을 준비하고 있는 것이다. 이를 위해서 바이오 문헌의 텍스트마이닝에서 가장 우수한 기술을 보유하고 있는 Ariadne Genomics사의 Pathway Studio를 이용하기 위해 2010년 말에 Ariadne Genomics사를 흡수, 통합하였다. 현재는 약 2년간의 통합작업을 거쳐 자체의 바이오 빅데이터를 이용하여 유용한 정보를 제공하는 사업을 준비하고 있는 것이다. Elsevier에서 자체적으로 약물 개발을 할 것인지, 아니면 이런 고급 정보를 제약회사에 판매하는 사업 모델로 갈 것인지는 확인되지 않았지만, 이제 곧 큰 비즈니스 모델화가 출시될 것이라는 것은 쉽게 짐작할 수 있다.
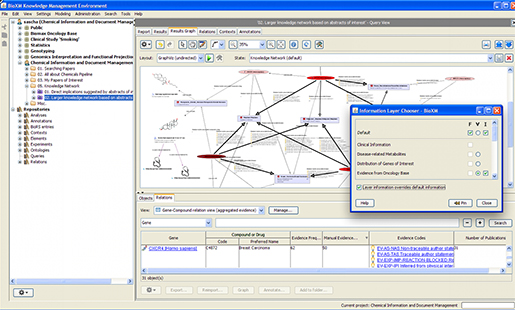
4-2. Biomax Informatics사의 Knowledge Management 시스템
독일의 MIPS의 스핀오프 기업인 Biomax Informatics사는 유전체 분석을 위한 파이프라인을 구축하여 수백여 종 이상의 유전체 기능 분석을 수행한 바 있다. 이 회사는 미국의 국립암센터와 협력하여 암에 관련된 모든 정보를 활용할 수 있는 플랫폼을 개발하게 되었다. 기존의 관계형데이터베이스로는 암에 관련된 복잡하고 난해한 정보에서 연관정보를 등록하고 추출하는 시스템을 구현하는 것이 쉽지 않았다. 따라서, 각 데이터에서 상관관계를 정의할 수 있는 플랫폼을 구축하여 정형화되지 않은 새로운 데이터들도 쉽게 현상을 알면 상관관계를 정의하여 빅데이터를 만들고 여기에서 의미있는 정보를 추출할 수 있는 서비스를 하게 된 것이다. 여기에서 확장하여 최근에는 병원의 다양한 정보를 등록하고 관련 데이터의 의미를 추출할 수 있는 비즈니스 모델을 구축한 바 있다. 아직은 플랫폼이 무거운 편이지만 빅데이터의 가장 큰 특징인 상관관계를 철저히 정의하는 새로운 플랫폼으로서 상당히 일찍 바이오빅데이터 시장에 자연스레 출발하였다고 볼 수 있다.
4-3. 자동화와 수동화가 이룬 업적 : Biobase
Biobase사는 매일 NCBI에 업데이트되는 서열정보와 문헌정보를 자동으로 다운로드 받아서 필터링 과정을 거쳐 등록되는 시스템을 구축하여 이 정보를 가공하여 의미있는 새로운 정보를 만들고 있다. 수년간에 걸친 수정보완을 통해 상당히 정교한 파이프라인을 내부 시스템으로 구축한 상태이다. 이 시스템에서 정보들을 필터링하여 새롭게 데이터를 가공하고 있는데 이 작업은 Biobase사의 인도지사에서 수행하고 있다. 인도지사의 60여명의 바이오전문가들이 추출된 문헌을 일일이 검토하여 새로운 지식 정보를 추출하고 등록을 하는데, 3단계 검증단계를 거쳐서 최종적으로 고객에게 서비스되는 형태로 만들어지는 것이다. 수 년 동안 지속적으로 문헌에서 의미있는 정보를 추출하는 작업을 하는 바이오전문가에 의해서 일일이 확인하고 검증하는 단계를 거치게 되는 것이다. 이렇게 만들어진 지식 정보는 제약회사, 육종회사들과 공동연구를 수행하는데 이용하거나 데이터를 연간 라이선스 형태로 일반 생물을 분석하고자 하는 사람들에게 판매하고 있다.
5. Codes 사업부의 미래
빅데이터를 논할 때 구글과 아마존을 함께 성공사례로
이야기를 하면서도 한편으로는 구글은 올바르게 빅데이터의 전망을 인식하여 사업으로 접근하고 아마존은 반대로 빅데이터를 놓쳐버렸다고
말하고 있다. 그 이유는 데이터에 대한 인식 및 사업화 차이를 두고 말하고 있다. 즉 구글은 구글 북스를 통해 스캐닝된
디지털자료를 데이터화해서 새로운 분석 및 활용에 시도하였으나, 아마존은 단순히 컨텐츠에 활용하였다는 것이다. 즉 1차적인
사업모델에는 적용하였으나, 그 부가적인 정보의 가치를 좀 더 확대하지 못했다는 것이다.
바이오의 모든 아날로그 데이터는 디지털화되고
데이터화하여 새로운 분석과 활용에 시도하겠다는 뜻을 가진 Codes. 최남우사장님이 수년전에 각 사업부의 이름을 정하면서 제안하신
이름이다. 어떻게 보면 몇 년 전에 바이오 빅데이터를 생각해서 미리 알맞은 이름을 제안하셨는지 모르겠지만, 새로운 생물정보
시장의 큰 흐름이 될 바이오 빅데이터를 어떻게 준비하느냐가 앞으로의 미래에 중요한 포석으로 자리 잡을 것이다. 또한 빅데이터는
데이터를 보유하거나 관리할 수 있는 주체가 가장 큰 이익을 얻을 수 있지만, 단순히 아이디어 및 컨텐츠를 발굴하는 사업 아이템도 큰
흐름이 될 것이다. 구글, 아마존, 페이스북과 같이 대량의 빅데이터를 직접 만들어내는 것은 쉽지 않지만, 공개화된 빅데이터에서
우리가 원하는 결과만을 추출할 수 있는 기술 및 아이디어 발굴이 중요하다. 이는 새로운 형태의 지식 유전을 확보하는 것과
동일하다. 최근 미국에서는 ‘데이터는 새로운 석유다’ 라는 말이 나오고 있는데, 이 말은 정제된 원유가 막대한 경제적 가치를
가져온 것처럼 데이터도 적절히 분석하면 큰 가치를 만들어낸다는 의미다. 기계공학을 전공하여 1학년 전공과목 때 교수님이
기계공학도가 되려면 모든 사물에 기계공학적인 관심을 가지고 주의 깊게 살펴보아야 한다고 말씀하신 기억이 떠 오른다. 기억(ㄱ)자
형태로 서있는 신호등이 제대로 지탱하기 위해서 몇 개의 줄이 필요한지 어떤 간격으로 줄이 설치되어야 되는지 등 실생활 속에서
기계공학적인 생각을 해 보라고 하셨다. 바이오빅데이터는 이와 마찬가지로 일반 생활속에서 우리가 원하는 것이 무엇인지 꾸준히
생각하고 정리할 수 있는 마인드가 중요할 것이다. 또한 바이오데이터는 다른 데이터에 비해 훨씬 높은 복잡성과 낮은 일치성으로 인해
가장 적절한 빅데이터의 모델이지만, 활용에 어려움이 있으므로 이를 해결하고자 하는 노력이 무엇보다 중요할 것이다.
데이터의 진짜 가치는 바다 위에 떠 있는 빙산과 같다.
처음에는 아주 조그만 부분밖에 눈에 보이지 않지만 수면 아래에는 많은 부분이 숨겨져 있다. 이것을 이해하는 혁신적 회사는 그
숨은 가치를 추출해 잠재적으로 엄청난 이득을 거둬갈 수 있을 것이다.
• 빅데이터가 만드는 세상(빅토르마이어쇤버거, 케네스 쿠키어 지음, 이지연 옮김-21세기 북스)
• 빅데이터 혁명(권대석지음, 21세기 북스)
• 빅데이터의 충격(시로타 마코토 지음, 김성재옮김, 한빛미디어)
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/138
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

