이번 16주년은 코로나 시대에 맞춰 비대면 온라인 기념식으로 간단히 진행되었습니다.
코로나 감염을 예방하기 위하여 마스크를 계속 착용해야 하는 불편함이 있지만 인실리코젠 직원들 모두 잘 실천해주셨습니다.
또한, 올해는 바이오 테크 분야에서 인공지능 기술의 선두를 위하여 인실리코젠의 자회사, AIDX를 설립하여 어려운 시기에도 한 단계 더 나아가게 되었습니다.

항상 느끼는 거지만 가을 하늘은 사계절 중 높고 푸르고 멋있는 것 같습니다.
인실리코젠 창립기념일에 항상 푸른 하늘을 볼 수 있어서 기쁩니다.

올해 인실리코젠에서 열정적으로 일하신 지 5, 10주년이 되신 분들을 위해 24K 황금열쇠를 준비하였습니다.
마음의 소리 : 금값 많이 올랐다는데..이런걸 준비해주시다니... 감동 ")

먼저 "생물정보 공유의 장"이라는 슬로건으로 2014년에 오픈한 인코덤(http://www.incodom.kr)의 역사를 되돌아보는 시간을 가졌습니다. 꾸준히 늘어가는 콘텐츠와 접속자 수에 우리 모두의 노력에 대한 보답과 뿌듯한 마음을 가졌으리라 여겨집니다.
이러한 결과에는 우리 모두의 노력을 이끌어내느라 수고해주신 지난 6년간 총 11분의 MD 분들이 있었습니다. 박선영 MD의 소감을 들어보겠습니다.


먼저 2년간 MD 협의회를 운영하면서 보이지 않게 어려움도 많았지만, 잘 이끌어주시고 도와주신 선배님들께 감사드리고, 글을 잘 작성해주신 인코인 여러분들께도 감사드립니다. 사실 글을 쓴다는 것이 단순히 있는 정보를 취합하는 것이라고 해도 내 언어로 쓰는 게 쉬운 일이 아닙니다.
여기서 귀찮음도 있고, 창작의 고통이 있을 수 있는데요, 그럼 그 대가는 무엇일까 생각해봤을 때 여러 가지가 있지만, 그 중 첫 번째는 내 지식수준이 올라가는 것이라고 생각합니다. 글을 단순히 옮기든 내가 풀어쓰든 조금이라도 관련 자료들을 읽게 되고 글을 쓰면서 해당 내용이 습득되고 정리가 되는 경우가 많은 것 같습니다.
현재 글 작성 독려를 위해서 보상제도도 생기고, 글을 쓰는 기준이 완화 및 자율화가 되었지만, 앞으로 작성 편집기나 QnA 창 등을 개선해 나가면서 글쓰기도 쉽고 더 활성화된 인코덤 사이트가 되길 바라고 있습니다.
앞으로 인코덤(incodom.kr) 개선을 위한 좋은 아이디어가 있으면 설문지나 MD 협의회를 통해 언제든지 말씀 부탁합니다. 남은 기간까지 마무리 잘하도록 하겠습니다. 감사합니다.


제가 2010년 3월 2일부터 출근해서 2020년 3월 3일까지 인실리코젠 소속이었으니까 약 10년 하고 2일 정도 인실리코젠에서 근속했었네요. 감개무량합니다.
연초에 디이프로 발령을 받고 나서 혹시나 이 자리에 서지 못하면 어떡하나 하는 쓸데없는 걱정을 잠깐 했는데 이렇게 축하해 주셔서 감사합니다.
어떻게 10년을 다닐 수 있었을까? 스스로 저를 냉정히 판단해 봤습니다. 입사 당시 저는 특별히 잘하는 건 없고, 그냥 여러 분야에 호기심만 많아서 딱히 어디 쓰기 모호한 사람이었습니다. 끈기도 집중력도 없었습니다. 이런 단점을 극복하고 살아남기 위해 오랜 시간 발버둥 쳤는데요, 스스로 의지가 있더라도 환경이 받쳐주지 않으면 할 수 없었을 겁니다. 비록 일은 항상 힘들었지만, 무엇보다도 저를 이끌어주시고 지지해 주시는 동료들이 함께 있는 조직이었기 때문에 이 자리에 설 수 있었습니다.
작년부터 10년 근속을 1년 남겨두고, 그동안 내가 이 회사에서 무엇을 남겼을까를 계속 고민해 봤습니다. 매출에 엄청난 영향을 주는 프로젝트를 성공적으로 마무리했는가? 회사에 돈을 많이 벌어왔나? 회사의 미래 먹거리가 될 만한 신기술을 개발했나? 업무 효율을 높일 수 있는 어떤 체계나 절차 같은 것을 만들었나? 서버실 온도 감시 시스템(https://insilicogen.com/blog/226) 은 제가 생각해도 잘 만든 것 같습니다. 이거 하나는 저 자신도 인정합니다. 큰 성과는 없었지만, 여러분들이 이런 성과를 만들어 낼 수 있도록, 찡그리지 않고 웃으면서 일 할 수 있는 어떤 분위기와 문화를 만드는 데는 제가 좀 이바지하지 않았나 생각이 듭니다.
이제 이렇게 인실리코젠의 공식 고인 물이 되어서 뿌듯하고요. 이제 어떻게 10년을 보내서 썩은 물이 될까 고민을 해봤습니다.
앞으로의 10년은 돈 많이 벌고, 잘 사는 게 목표입니다. 제가 저 혼자 잘 먹고 잘살려고 이런 목표를 세우는 것이 아니라, 제 후임 분들께 이 분야에서 열심히 일하면 저 사람 보다는 잘 살 수 있겠지라는 어떤 기준이 될 수 있도록 잘 살고 싶습니다. 제가 사장님 대표님 이사님 실장님 팀장님들을 보면서 바랬던 목표보다 더 큰 목표를 여러분들이 가질 수 있도록 잘 살겠습니다. 감사합니다.

안녕하세요? 인실리코젠 FED팀에서 웹 UI 개발을 담당하고 있는 김태영 선임입니다. 입사해서 처음 맞은 창립기념일에서 장기근속상을 수상하신 분들이 참 대단하다는 생각을 했는데 어느새 제가 이 자리에 있다니 시간이 참 빠르다는 생각과 함께 지난 시간들을 되돌아보는 계기가 되는것 같습니다.
입사 당시 우리 회사는 프로젝트들이 한꺼번에 몰리는 특징이 있음을 알게 되었고 이런 환경에 어떻게 대응할 수 있을까 고민하는 시간이 많았던것 같습니다. 시행착오도 있었지만 작업가이드를 세우고 프론트개발용 스케폴딩을 미리 준비해서 팀원간 협업할 때 의존성을 줄여서 충돌로 소모되는 시간이 줄었고 프로젝트마다 이뤄지는 반복작업이 줄어서 지금은 보람을 느낍니다.
개인적으로는 가정에도 충실할 수 있도록 배려해주신 사장님외 많은 선배 동료 임직원 분들 덕분에 가능했던 시간이었습니다. 이 자리를 빌어 감사 드립니다. 부족하고 아쉬운 부분도 많지만 예쁘게 봐주시고 조직에 도움이 되는 일원이 되도록 앞으로 더 화이팅하겠습니다.

지나가는 시간이 너무 빠른 것 같습니다. 흥덕으로 이사하고 처음 입사자였었는데, 입사 후 참석했던 시무식이 새록새록 기억에 남고, 이 사무실과 지내온 시간이 같다고 생각하니 감회가 새롭습니다. 혼자의 힘으로 지내온 게 아니라 많은 분의 도움으로 여러 해의 시간을 보낼 수 있었던 것 같고, 모두 도와주셔서 늘 감사하게 생각하고 있습니다. 더욱 발전하라는 의미라고 여기고 노력하도록 하겠습니다. 감사합니다.
- Sardorbek Muminov - 5년 장기근속자

Wow. 5 years have passed quickly. I didn’t even realize I had worked for 5 years. The reason I didn’t notice the passage of time was probably due to interesting projects, friendly colleagues, and the healthiness and sincerity of the working environment. The first year I joined Insilicogen, I was once again convinced that I had chosen the right company quickly after a few weeks. Being a member of Insilicogen has helped me maintain work-life balance, obtain more knowledge, learn new technologies, and put them into practice. On this Anniversary I appreciate all our hard work and dedication. Congratulations on this big occasion and many wishes for future success. Happy anniversary.

창립기념일 하면 떠오르는 게 많습니다. 우선 제 입사일은 2015년 9월 1일로 창립기념일일 10월 1일과 딱 한 달 차이가 나지요. 2015년 10월 1일인 입사 한 달이 되었을 무렵 11주년 창립기념일에 사장님과 함께 케익을 자르던 것이 기억납니다.
또 작년이었던 15주년 창립기념일 행사도 브랜드위원회로서 함께 기획하고 사회도 진행했었습니다. 이런 추억과 경험들이 쌓이다 보니 어느덧 5년이라는 시간이 흘렀고, 인실리코젠이 성장해온 것처럼 저도 함께 성장해온 동기 같은 느낌이 드네요.
늦깎이 사회초년생으로 인실리코젠에서 사회에 첫발을 내디디고, 결혼과 자녀까지 인생의 중요한 시점을 인실리코젠과 함께 해왔습니다. 앞으로도 저희 아이가 커가듯이 저도 성장하고, 인실리코젠도 함께 성장하여 지금 5년 전 제 모습을 돌이켜보며 흐뭇하게 미소 짓는 것처럼 그때도 지금의 제 모습을 생각하며 미소 지을 수 있도록 노력하겠습니다. 감사합니다

우선 여러 면에서 어려운 시기를 보내고 있는 와중에도 이렇게 의미 있는 자리를 마련해주신 사장님과 정이사님께 감사의 말씀을 드립니다. 지금에 와서 생각해보면 벌써 5년? 이라는 생각도 들지만, 제 인생에 있어서 그 어느 때보다 밀도 높게 보낸 5년이었던 것 같습니다.
겹겹이 들어차 있는 인코에서의 5년이라는 시공간 속에는 때로는 힘들었던 기억들과 가끔은 재미있었던 추억들, 그리고 끊이지 않았던 오늘에 대한 고민과 놓을 수 없었던 내일에 대한 걱정들이 빈틈없이 가득 차 있었던 것 같습니다.
지금은 그 힘듦의 대부분이 성장의 원료로, 고민과 걱정의 상당 부분은 이제 미래에 대한 희망과 기대로 치환될 수 있었는데, 이것은 오롯이 생명정보를 통해 세상을 이롭게 하려는 비전 속에서 서로에게 힘이 되어주었던 모든 인코인들의 사랑과 배려 덕분이었던 것 같습니다.
지난 5년간 많이 아껴주시고 항상 지지해주셨던 모든 인코인들에게 감사드리며 앞으로도 이 인코 네트워크 시너지가 더욱 견고하게 확장될 수 있도록, 그리고 이를 바탕으로 우리가 더욱 좋은 방향으로 나아갈 수 있도록 저 역시 노력하겠습니다.
감사합니다.

장기 근속하신 인코인을 보며 모두 인실리코젠의 인재상(성실, 열정, 배려, 소통, 학습)으로 성장하였음을 느꼈습니다.
16주년 기념식을 마무리하며 사장님께서 10주년에 말씀하셨던 "경영은 주변 사람들을 행복하게 하는 것" 이라는 미시다고노스케의 경영철학에 대하여 재언급하셨습니다. 16년 동안 회사와 직원들이 성장을 리드하고 비즈니스를 확대하여 회사를 키우는 사장님의 보이지 않는 노력들의 본질(직원들의 행복-> 건강, 사랑, 경제)에 대해 알 수 있었습니다. 다음 17주년에는 인실리코젠의 자회사인 iBreeding(아이브리딩-데이터 육종기업), D.iF(디이프-데이터식품 선도기업), AIDX(에이아이디엑스-AI 의료진단기업)와 함께 더욱 성장한 회사로 찾아뵙겠습니다.
작성 : 브랜드위원회
Posted by 人Co


 人CoINTERNSHIP_지원서_2020.doc
人CoINTERNSHIP_지원서_2020.doc






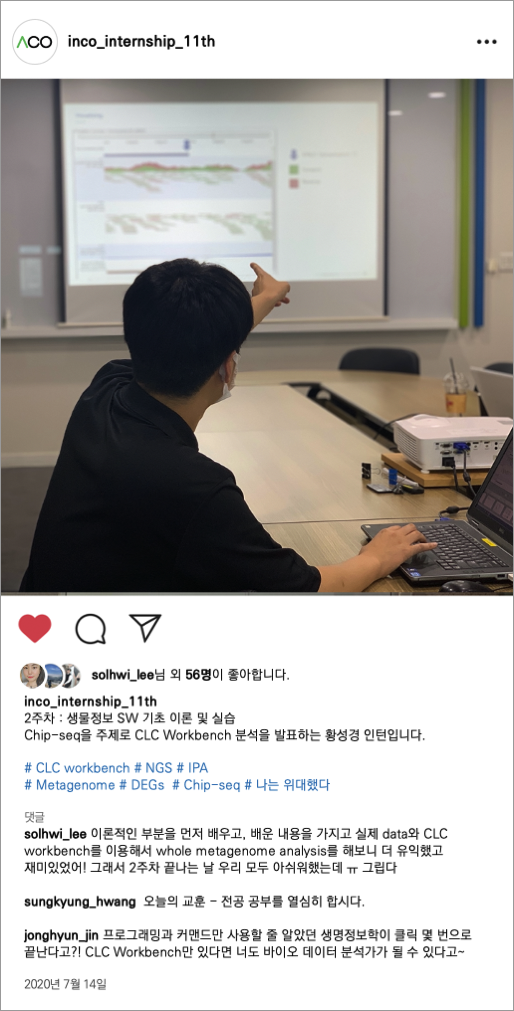

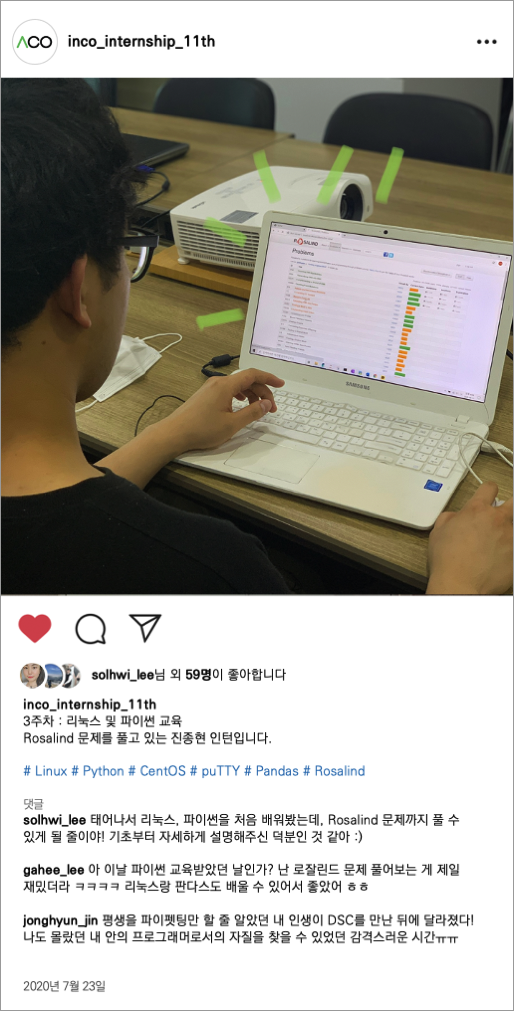











 人CoINTERNSHIP_지원서_2020.doc
人CoINTERNSHIP_지원서_2020.doc













 입사지원서_성명_지원부문_20200000.docx
입사지원서_성명_지원부문_20200000.docx
