
[Quipu Issue Paper] Genome Annotation Ⅴ- Functional annotation(상동성 기반의 Annotation)
- Posted at 2010/03/22 11:19
- Filed under 생물정보
연재 순서
1. Assembly
2. Variation study
3. Expression study
4. Epigenomics
5. Genome Annotation
6. Next Generation Bioinformatics
7. Data Management for web 2.0 Era
8. Semantic Network for Integrated Biology Data
9. Gene Network Discovery by Text-mining
10. Centralization for High-throughput Data Analysis
이번 연재에서는 유전자의 기능을 분석하는 Functional annotation 중에 먼저 상동성 기반의 Annotation에 대해 알아보겠습니다.
2-4-2. Functional annotation
A. 상동성(homology) 기반의 Annotation
유전체 서열에서 유전자의 위치와 구조 정보를 파악하여 유전자의 서열을 분석한 뒤 그 서열 정보를 통해 유전자의 기능을 유추 한다. 가장 보편적으로 유전자의 기능을 분석하는 방법이 상동성 기반의 분석이다. 다만, 상동성 분석에 기반한 유전자 기능 유추 시 사용되는 데이터베이스에 따라 노이즈 발생률이 차이가 나므로 데이터베이스 구축에 많은 노력을 기우려야 한다. 분석하려고 하는 종과 동일한 종의 단백질 서열을 1차 데이터베이스로 구축하고 다음으로 유연 관계가 가까운 종을 대상으로 2차 데이터베이스를 만드는 피라미드 형태의 데이터베이스 구축이 필요하다. 또한 각 데이터베이스에 맞는 상동성 경계 값(cutoff) 조정이 필요하다. 단백질 수준에서의 상동성은 보통 높게는 1e-200에서 낮게는 1e-4 까지 적절한 수준으로 조정을 하게 된다. 그러나 DAN 수준에서의 상동성은 아무리 높은 e-value 경계 값이라도 신뢰할만한 정보가 되지 않는다고 말한다. 따라서 e-value 뿐만 아니라 identity, HSP coverage 등이 상동성 레벨을 정하는 기준이 되기도 한다.
분석에 이용되는 데이터베이스는 그 특성에 따라 약간의 차이가 있다(표 1). 단백질의 기능 규명을 위해 단백질의 1차 구조인 서열 정보부터 2차 구조정보인 도메인 정보, 3차 구조정보에 해당하는 PDB 정보 등 다양한 데이터베이스가 이용된다. 뿐만 아니라 세포내 위치 정보를 통해 기능을 유추하기도 하므로 세포내 위치 정보까지 가능한 모든 정보를 분석할 수 있는 흡사 유전자 기능 백화점과 같은 유전자 기능에 대한 정보 분석이 요구된다. 이러한 통합적인 유전자 기능 분석을 수행하기 위해서는 다양한 알고리즘과 데이터베이스, 분석 프로그램들의 유기적인 네트워크가 구축되어야 하며, 수많은 데이터의 입출력이 이루어지므로 데이터의 효율적인 관리를 위한 시스템도 연계되어야 되므로 상당히 복잡한 대규모 분석 시스템이 요구된다. BioMax사에서는 초기 인간 유전체 기능 분석부터 수백 종의 미생물, 다양한 척추동물, 식물 등의 기능 분석을 수행한 Pedant-Pro(http://www.biomax.com/products/pedantpro.php)라는 유전체 구조, 기능 분석 자동화 시스템을 서비스하고 있다.
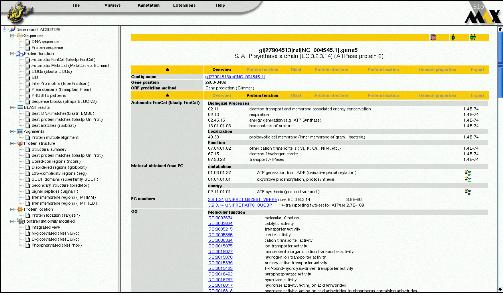
Pedant-Pro에서는 크게 세 가지 카테고리로 구성된 데이터베이스를 통해 단백질의 기능을 규명하고 있다. 첫 번째, 단백질의 1차 구조인 서열정보를 이용한 분석으로 GO, MetaCat, FunCat, EC, COGs 데이터베이스를 활용한다(표 2).
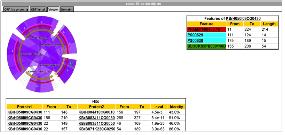
단백질의 서열 정보에 기반하여 얻어진 단백질 내의 도메인 정보는 프로파일 과정을 통해 서로 비슷한 도메인 프로파일을 갖는 단백질들 간의 클러스터 분석에 이용된다. 단순 서열 상동성에서 벗어나 좀 더 구체화된 기능을 중심으로 유전자의 기능을 유추하는 방법을 Pedant-Pro에서 제시하고 있다(그림 9). 유사한 방법으로 synteny 구조를 이용한 ortholog 분석이 있다. 유연관계가 가까운 종과의 synteny 분석을 이용해 유전자의 기능 뿐 아니라 염색체 내의 물리적 위치정보까지 이용하여 유전자의 기능을 규명하게 된다. 이들 방법들은 종간 ortholog 분석에 기초한 비교유전체 분야에 주로 이용되며 그 자세한 내용은 다음에서 다루도록 한다.
다음 연재에서는 서로 다른 종간의 상응하는 유전자 조합 및 구성을 분석하여 진화론적인 유연관계를 밝히는 비교유전체 분석에 대해 알아보겠습니다. 많은 관심 부탁드립니다.
참고문헌
1. Lowe, T.M. and Eddy, S.R. (1997) tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 25, 955-964.
2. Lewis SE, et al. (2002). Apollo: a sequence annotation editor. Genome Biology. 12, research0082
3. Noh SJ, Lee K, Paik H, Hur CG. (2006) TISA: tissue-specific alternative splicing in human and mouse genes. DNA Res. 13, 229-243
4. Stanke M, Schoffmann O, Morgenstern B, Waack S. (2006) Gene prediction in eukaryotes with a generalized hidden Markov model that uses hints from external
sources. BMC Bioinformatics. 7, 62.
5. Burge, C. and Karlin, S. (1997) Prediction of complete gene structures in human genomic DNA. J. Mol. Biol. 268, 78-94.
6. Salamov AA, Solovyev VV. (2000) Ab initio gene finding in Drosophila genomic DNA. Genome Res. 10, 516–522.
7. Majoros, W.H., Pertea, M., and Salzberg, S.L. TigrScan and GlimmerHMM: two open-source ab initio eukaryotic gene-finders Bioinformatics 20, 2878-2879.
8. G. Parra, E. Blanco, and R. Guigó, (2000) Geneid in Drosophila Genome Research 4, 511-515.
9. Haas BJ, Salzberg SL, Zhu W, Pertea M, Allen JE, Orvis J, White O, Buell CR, Wortman JR. (2008) Automated eukaryotic gene structure annotation using
EVidenceModeler and the Program to Assemble Spliced Alignments. Genome Biology 9, R7
10. Korf I. (2004) Gene finding in novel genomes. BMC Bioinformatics. 5, 59.
11. Kan, Z., Rouchka, E.C., Gish, W., and States, D. 2001, Gene structure prediction and AS analysis using genomically aligned ESTs, Genome Res. 11, 889–900.
12. Eyras, E., Caccamo, M., Curwen, V., and Clamp, M. 2004, ESTGenes: AS from ESTs in Ensembl, Genome Res. 14, 976–987.
13. Kent, W.J. 2002, BLAT-The BLAST-Like Alignment Tool, Genome Res. 12, 565–664.
14. Florea, L., Hartzell, G., Zhang, Z., Rubin, G.M., Miller, W. 1998, Computer program for aligning a cDNA sequence with a genomic DNA sequence, Genome Res. 8,
967–974.
15. Huang X, Adams MD, Zhou H, Kerlavage AR. (1997) A tool for analyzing and annotating genomic sequences. Genomics. 46, 37–45.
16. Wu TD, Watanabe CK. (2005) GMAP: a genomic mapping and alignment program for mRNA and EST sequences. Bioinformatics. 21, 1859–1875.
17. Birney E, Clamp M, Durbin R. (2004) GeneWise and Genomewise. Genome Res. 14, 988–995.
Posted by 人Co
- Tag
- annotation, biomax, COG, FunCat, GO, homology, insilicogen, MetaCat, NGS, PDB, Pedant-Pro, Pfam, Uniprot, 단백질, 비교유전체, 상동성, 인실리코젠
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/61
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

