
의료 영상 분석의 개요
- Posted at 2020/09/27 18:26
- Filed under 지식관리

4차 산업혁명 시대에서 인공지능은 다양한 분야에서 쓰이고 있고, 그중 의료 영역 내에서도 적용 범위가 확대되어 가고 있습니다. 영상 이미지로 정상 유무를 판정하거나 병리 영상 데이터 분석에 쓰이는 판독보조, 음성 인식 의무기록이나 생체 신호 모니터링과 같은 진료보조, 유전체 데이터 분석 기반의 신약개발 등 인공 지능 기반의 의료 진단 기술이 개발되고 있으며, 특히 의료 영상 판독 분야에서 인공지능이 매우 유용하게 쓰이고 있습니다.

Image Acquisition
우선 이미지를 얻는 원리에 대해서 간단히 알아봅시다.
카메라의 기본 원리는 Light source로부터 빛을 쏘아서 어떤 물체에 닿으면 특정 빛이 반사되고, 이 반사된 빛을 센서로 취득해서 전기신호로 바꿔주면 명암차이로 영상이 만들어지게 됩니다. 카메라는 light source가 가시광선이고 이를 취득할 수 있는 CCD, CMOS 센서를 쓰는 데 반해, 적외선을 쏘고 이를 detection 할 수 있는 센서를 놓으면 적외선 카메라, X-ray 신호를 주고 이를 detection 할 수 있는 센서를 놓으면 X-ray 시스템이 됩니다.
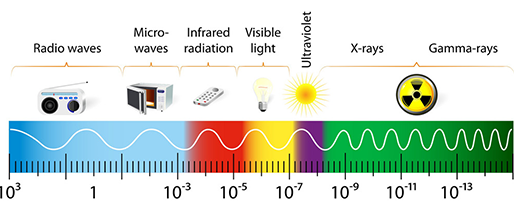
그럼 light source에 따른 다양한 의료 영상 데이터에 대해 살펴보겠습니다.
가시광선을 이용한 의료 영상 :
- Endoscopy (내시경) : 위, 장 내시경 검사 시 사용하는 것으로, 내시경 앞부분에 light source와 CCD 센서가 모두 있어서 영상으로 보여줍니다.
- Microscopy (현미경) : 조직 검사 시 현미경의 접안렌즈, 대물렌즈를 이용해 작은 물체를 크게 확대해서 보여줍니다.
방사선을 이용한 의료 영상 :
- X-ray : X-tube에서 light source를 내보내고 몸을 통과하는데, 각 부위 조직의 투과된 x-ray intensity 차이로 영상을 만들어냅니다.
- CT (Computed Tomography) : 인체의 단면 주위를 돌며 다각도에서 x-ray 영상을 찍고, 여러 장의 2D x-ray 이미지를 합쳐 한 장의 3D 영상 이미지로 만듭니다. 수 초 내로 짧은 시간 안에 3D 영상을 얻을 수 있지만, 방사선에 노출되고 조영제를 사용하여 몸 밖으로 배출이 잘 안 될 수 있다는 것이 단점입니다
- PET (positron emission tomography) : 양전자를 방출하는 방사성 의약품(방사성 포도당)을 몸에 주입 후, 인체의 360도에서 이를 detection 후, 3D 영상 이미지로 만듭니다. 포도당 대사는 암세포에서 비정상적으로 높으므로 PET에서 밝게 나와 암 조기진단에 유용하게 쓰입니다. 신진대사를 볼 수 있어 조기진단이 가능하지만, 방사선을 몸에 주입하고 비싸다는 단점이 있습니다.
자기장을 이용한 의료 영상 :
- MRI (Magnetic Resonance Imaging) : light source는 아니지만, 자기장을 걸어주어 몸 안의 수소 원자들이 근육, 지방 등 tissue에 따라 도는 속도의 차이를 바탕으로 3D 영상을 만듭니다. 방사선 노출이 없어 몸에 유해하지 않고, brain처럼 soft tissue들을 잘 구분해서 볼 수 있으나, 비싸고, 찍을 때 소음이 나며, 영상을 얻는 데 시간이 오래 걸리는 단점이 있습니다.
이 밖에 심장, 태아 검사를 위한 초음파나 망막 단층검사를 하기 위한 근적외선을 이용한 영상 등이 있습니다.
Digital Image Acquisition
이렇게 찍은 영상들은 디지털화를 하는데요, 격자로 쪼개서 화소들의 이차원 배열로 표현하는 sampling, 각 화소의 컬러 범위를 결정하는 quantization을 거칩니다.
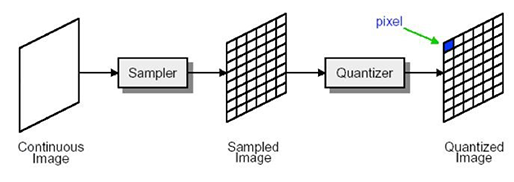
[Fig. 2] Digital image acquisition process
이때, 디지털화된 이미지는 다음의 요소들로 표현합니다.
- Resolution : Sampling이 이루어지는 매트릭스 갯수 (이미지 사이즈)
- Intensity : 각 sampling point (2D에서는 pixel, 3D에서는 voxel) 에서의 값
- Gray level : quantization의 단계 (보통 0~255까지 256레벨)

그렇다면 이 디지털 이미지가 병원 시스템에서 어떻게 동작할까요? 영상 장비에서 얻은 디지털 의료 영상 이미지는 병원의 PACS 서버로 전송되고, 의사들이 client system을 이용해서 영상을 띄워서 봅니다.
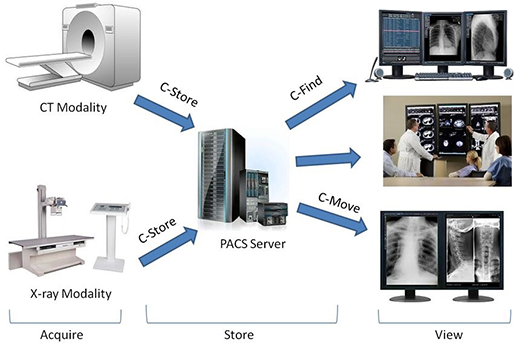
여기서 PACS는 의료 영상 저장 전송 시스템을 말하며, 디지털 영상 이미지를 DICOM이라는 국제표준 규약에 맞게 저장, 가공, 전송하는 시스템입니다. DICOM으로 저장될 때 판독결과와 진료기록이 추가될 수 있고, 네트워크를 통해서 병원 내외의 단말로 전송할 수 있습니다.
DICOM (Digital Imaging and Communications in Medicine)
그럼 의료 영상을 다루기 위해 DICOM에 대해 더 살펴보겠습니다. DICOM은 의료용 기기에서 디지털 영상 표현과 통신에 사용되는 표준을 총칭하는 말로 북미방사선학회(RSNA)에서 1990년대에 정한 국제 표준입니다. 의료 빅데이터를 분석할 때 데이터를 표준화하고 정제하는 것이 어려운데, 여러 분야 중 그나마 영상 분석이 수월한 것은 이 DICOM 국제 규약에 의해 표준화 돼있기 때문일 것입니다.
하나의 DICOM single format (.dcm)은 기본적으로 header와 image 정보가 있습니다.
- Header
- header에는 태그별로 환자 정보, 영상 취득 날짜 등 부가적인 meta 정보를 담고 있습니다. 주로 참고할 만한 태그로 (0008,~)에는 modality 및 study에 대한 정보, (0010,~)에는 환자 정보, (0028,~)은 dimensions 및 scale 등 이미지 정보들을 담고 있습니다.
- (0028,~) 이미지 정보 예시로는 3차원 이미지의 x,y,z가 몇 개의 voxel로 구성되어 있는지 나타내는 dimensions, 한 voxel의 x,y,z가 각각 몇 mm인지 나타내는 voxel spacing, 영상마다 보기에 최적화된 pixel 범위 기준인 window center, window width 등이 있습니다.
- 이 header 정보들은 이미지에서 필요부분을 추출할 때 기준방향과 pixel 및 voxel의 실제크기 등 변환 연산에 필요한 정보로 이용되고, 이런 정보들을 바탕으로 이미지들의 voxel spacing을 맞춰야 유의미한 분석이 됩니다.
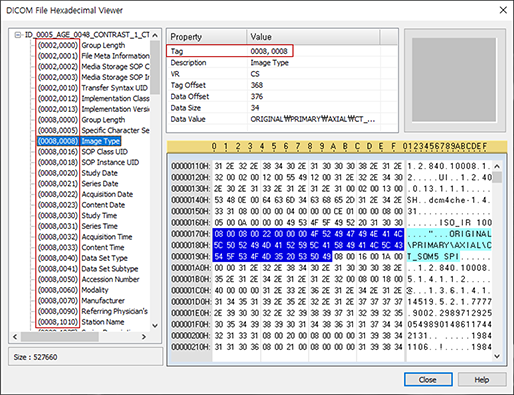
[Fig. 4] 프리웨어인 Sante DICOM Viewer 프로그램을 이용하여 본 한 장의 DICOM 파일의 header 정보
- Image data
- 압축된 비트맵(bitmap) 또는 압축되지 않은 형식(jpeg, gif..)의 이미지 정보를 담고 있습니다. 이미지 매트릭스에 한 pixel마다 intensity 값이 있습니다.
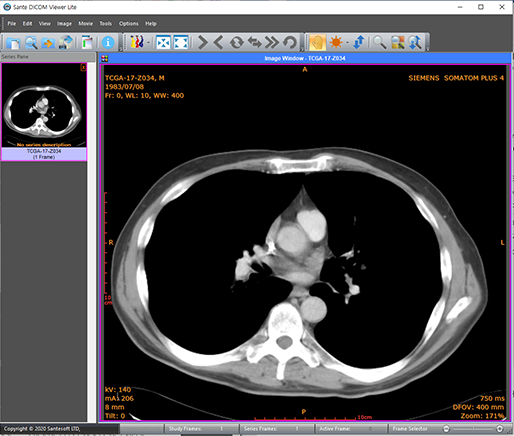
[Fig. 5] 프리웨어인 Sante DICOM Viewer 프로그램을 이용하여 본 한 장의 DICOM 파일 이미지
이외에 Nifti (nii) 등 다른 포맷들이 있는데, 파일이 두 개로 나누어져 있는 경우 영상 정보와 헤더 정보가 따로 있습니다. (예시: Analyze (hdr/img), Raw data (mhd/raw))

의료영상을 시각화하여 확인하기 위해서는 다음과 같은 도구를 이용합니다. 간단한 사용방법과 직관적인 사용자 Interface를 갖고 있는 Sante DICOM Viewer, segmentation을 잘 그려주는 것이 장점인 ITK-snap, 병리 영상 분석에 최적화된 Qupath, 이 밖에 MITK, MRICron, 3D Sicer, ImageJ 등을 활용합니다.
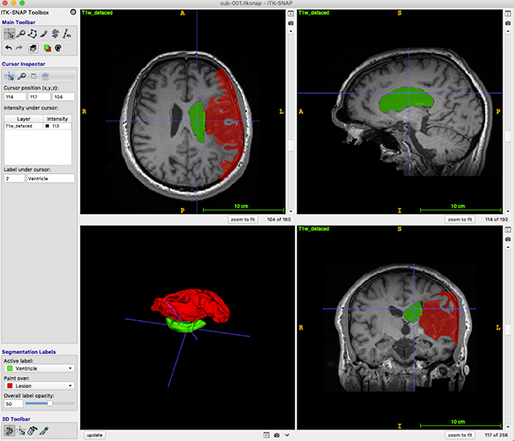
[Fig. 6] ITK-SNAP 을 이용한 brain MRI
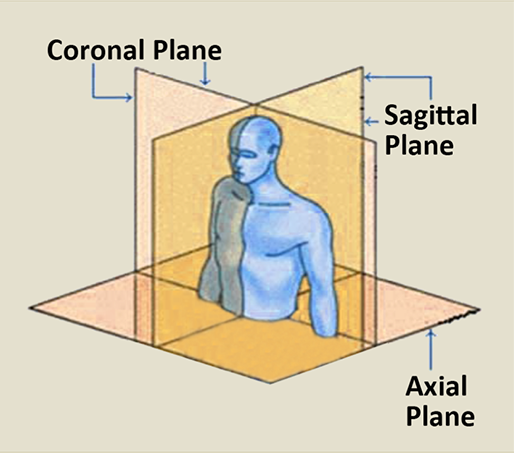
3D 영상은 3가지 방향에서 볼 수 있는데, top-down 방식의 axial 뷰, 몸을 left-right로 나누는 sagittal 뷰, anterior-posterior로 나누는 coronal 뷰가 있습니다.

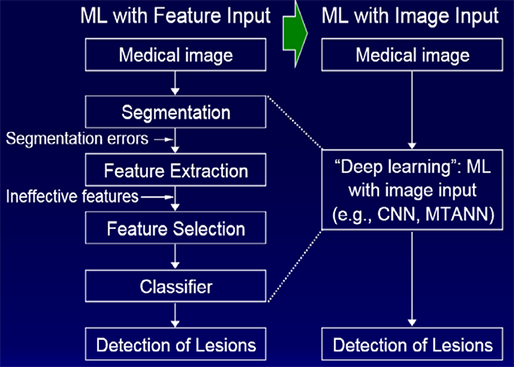
의료 영상은 대량의 데이터를 얻기 힘들고, 지도학습에 필요한 레이블 정보를 얻는 것은 더욱 어렵습니다. PACS 시스템을 이용해서 병원마다 많은 영상 데이터는 있지만, 제도적, 사회적 이슈로 인해 데이터 접근이 쉽지 않고, 병변의 위치를 레이블링하는 것도 숙련된 전문의의 판독이 필요한데 PACS에서 얻는 영상들은 레이블링이 되어있지 않은 경우가 많으므로 필요한 데이터 자원을 최소화하면서 좋은 성능을 기대할 수 있는 방법론의 개발이 중요합니다.
또한, 3D 영상이 많고 영상의 크기가 상당히 큽니다. 2015년 이미지넷 대회에서 1위를 차지한 영상 분류에서 기준 영상은 짧은 변 기준으로 최대 640픽셀 크기를 입력으로 받았는데, 흉부 X ray영상은 한 변이 2,000픽셀 이상이고 유방촬영영상은 4,000픽셀이 넘으며, 병리 영상은 10만 픽셀보다 큰 경우가 대부분입니다. 연산 능력을 감당할 수 있는 환경이 필요한 것뿐만 아니라 이를 효율적으로 처리할 수 있는 알고리즘의 개발이 필요합니다. 그리고 객체의 크기가 상대적으로 굉장히 작은 경우가 많기 때문에 이를 잘 검출할 수 있는 기술도 필요로 합니다.
이 밖에 같은 질병의 같은 조직 영상이라도 나이에 대한 보정이 필요하고, 영상 이미지 외에도 성별, 흡연, 음주여부 등의 기타 정보들을 분류 분석에 사용하기도 합니다.

Classification
전형적인 computer vision 문제로, 영상 이미지를 보고 정상인지 환자인지 분류합니다. 보통 의료 영상 분석은 분류하는 것이 주목적입니다.
Segmentation
영상에서 organ(장기)나 nodule(결절)과 같이 관심 있는 특정 영역을 추출합니다. intensity값으로만 구분하는 thresholding, 시작점과 비슷한 값을 assign해 나가는 “seeded” region growing 등 다양한 방법이 있습니다.
Enhancement
영상에 noise가 있거나 해상도가 낮은 경우 영상 퀄리티를 높이는 방법입니다. Intensity의 분포를 가지고 value를 바꿔주는 histogram processing, pixel 주변을 보고 블러를 통해 노이즈를 감소하는 smoothing 및 영상의 edge 부분을 강조하는 sharpening과 같은 spatial filtering이 있습니다.
Registration
각기 다른 영상들을 모았을 때 비교할 수 있게 잘 맞춰주는 방법입니다. 파노라마나 시차를 두고 영상을 취득했을 때 이미지를 합침으로 이미지가 이어진다거나 차이점을 볼 수 있게 하는 방식입니다.



-
https://terms.naver.com/entry.nhn?docId=2117497&cid=44414&categoryId=44414
-
https://pdfs.semanticscholar.org/7f71/b738b186d7a2a96aa5a9664650c4a3a769a2.pdf
-
https://www.ipfradiologyrounds.com/hrct-primer/image-reconstruction/
-
https://www.doctorsnews.co.kr/news/articleView.html?idxno=134361
Posted by 人Co
- Response
- No Trackback , No Comment
- RSS :
- https://post-blog.insilicogen.com/blog/rss/response/358
Trackback URL : 이 글에는 트랙백을 보낼 수 없습니다

